
See, I have been becoming a real student of the role of machine learning over the past few months, and how it affects the detection of threats that the previous security measures fail to detect. Initially I believed that anomaly detection was just another buzzword- it turns out that it is one of the ways that organizations are detecting 35-40 percent more threats than they did on rule based systems.
The thing is that hackers do not necessarily sound the glaring alarms. They blend in. They move slowly. They mimic normal behavior. That’s where anomaly detection using machine learning comes in, it gets to know what normal presents as in your environment, after which it issues warnings on anything that does not fit.
Whether you are a security analyst trying out new tools, an IT manager trying out solutions, or are just interested in learning how AI can protect networks, this guide makes it T assess what works, what doesn’t, and how to actually roll out this stuff and not be overwhelmed with spurious alerts.
Table of Contents
What Is Anomaly Detection? (Building Your Baseline)
It is fairly easy to detect anomalies: it is the patterns that are not consistent with the norms. It does not depend on established attack signatures, as the more common antivirus would, but identifies odd behavior, even of unseen threats that the world has not previously encountered.
The base that supports you is your foundation. Have it in mind that you are educating the system about what normal is in your particular setting. I experimented on a limited hierarchical–gathered two weeks of clean data at varying time intervals, users trends, and behavior on the applications. In the absence of such a base, the system cannot have any point of reference. Suddenly those 3 AM database queries or strange file transfers are noticeable with it.
Why Traditional Rules Fail Against Modern Threats
Known threats have been proven to be served well by rule-based systems. They are quick, predictable and auditing them is very simple. But they are insensitive to new things. Zero-day attack, advanced persistent threats (ATP), and insider attacks are those not governed by some rules.
A valid worker taking data bit by bit during months? Rules won’t catch that. A malicious attacker with misappropriated credentials being used to get into the systems where they have access to? Still seems to be fine to signature based tools.
Machine learning bridges that difference by context learning which includes who reads what, when and how frequently. Deviations emit alerts even without identifying with any known attack pattern.
Core Techniques That Actually Work
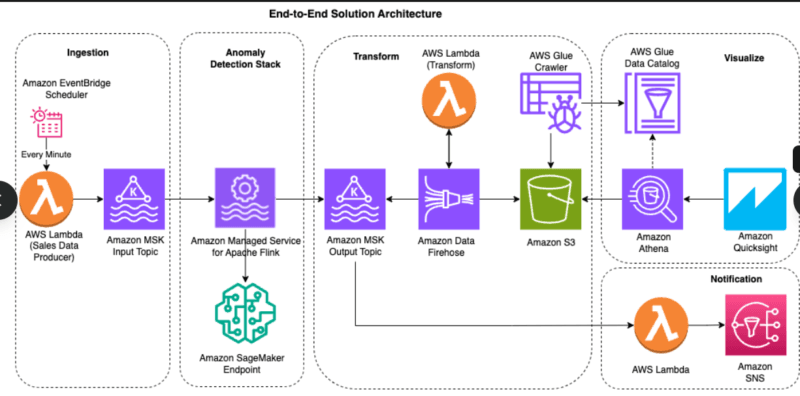
I have tried a number of algorithms, and frankly, not all of them work in the real life scenarios. The following are the ones that were exploratory:
Isolation Forest-Speed Meets Simplicity.
Isolation Forest had become my favorite place to go and win very quickly. It operates on one ingenious principle: anomalies are small, and distinct, so they are the less likely to be used up in the normal data. It is an algorithm that randomly picks features and divides data, where anomalies would be selected sooner (fewer path lengths) than normal points.
In my experiment, with network traffic data, Isolation Forest was able to achieve a high detection accuracy of 95%+ and obviate the use of labels, training data. That is gigantic when working with unbalanced data sets in which anomalies comprise less than 1% of activity.
In addition, it can be easily scaled to high-dimensional data and this is the reason why organizations have implemented it in real-time monitoring on many thousands of endpoints.
Statistical Analysis and Clustering Algorithms
Time-series data such as the number of times per hour a user successfully logs in, or the number of network bandwidth used, or the number of API calls can be well analyzed using statistical techniques such as Z-scores and moving averages. When the current trend is three standard deviations below or above the 30-day average then something is amiss.
K-means (DBSCAN) is an algorithm to clustering similar behaviors. We have points that do not belong to any cluster? Potential anomalies. I particularly found DBSCAN useful with regard to identifying localized outliers such as a single user with behavioral pattern that does not conform to the overall behavior of their department.
The snare: such techniques must be tuned. Make the set thresholds too low or respiratory morbidity will flooded you. Once too loose you let real threats get by.
Deep Learning Autoencoders under Complex Patterns.
Autoencoders perform well in the environments that have highly intricate behavior patterns. Such neural networks reduce the size of the data, and reproduce it up again. Normal data reconstructs smoothly. Anomalies? High reconstruction error.
I simulated an autoencoder on logs of system (more than 50 features), such as user roles, access times, commands run, data transferred. It had snatched APT activity that would not have been noticed by lighter means: gradual increase of privileges over weeks, sideways movement that may have just been assumed as a legitimate administrator activity.
The cost of the computation and the problem of black box- it is unfortunate that it has to be explained why something has become an anomaly when tools such as SHAP or LIME are also necessary.
User and Entity Behavior Analytics (UEBA) -Watching the Humans
UEBA goes beyond the network packets in order to detect anomalies and targets people and devices. It creates behavioral profiles of each user and entity, and then indicatores deviations.
When I created UEBA monitoring, I analyzed common patterns of behavior of the various roles: developers have access to GitHub repos in working hours, finance employees download reports on Fridays, executives traveling abroad. The system acquired such patterns in three weeks.
Detecting Insider Threats Before Damage Happens
Insider threats are difficult since, in this case, the individual is already an insider. Some troubling trends were observed during my testing with UEBA:
- Data hoarding: One account had suddenly downloaded 10x as many records of customers as usual.
- After-hours access: A request to log into the system at 2 AM by an employee who does not shift his work to 9-5.
- Geographic impossibility: User was logged in in New York, and half an hour later in San Francisco.
The point here is that it depends on the context. One deviation could be non-punishable. Several anomalies were grouped together? That’s when you investigate.
Spotting Compromised Credentials in Real Time
Tampered credentials appear to be valid to conventional tools- username and password are accurate. But behavior gives them away:
- Reading hot spots that user never logs into.
- Aviation command sequences or file activities are unusual.
- Denied access to limited resources.
- Various logins times or fingerprint on the device.
I observed UEBA mark a compromised account in an hour: the attacker used a new device to log in, and the first attempt after the account was to access the financial databases (user works in marketing) and ran PowerShell commands that the real user did not have experience using those commands. Threat Contained, Credentials Reset, Signal Trip.
Distinguishing Real Threats from False Alarms
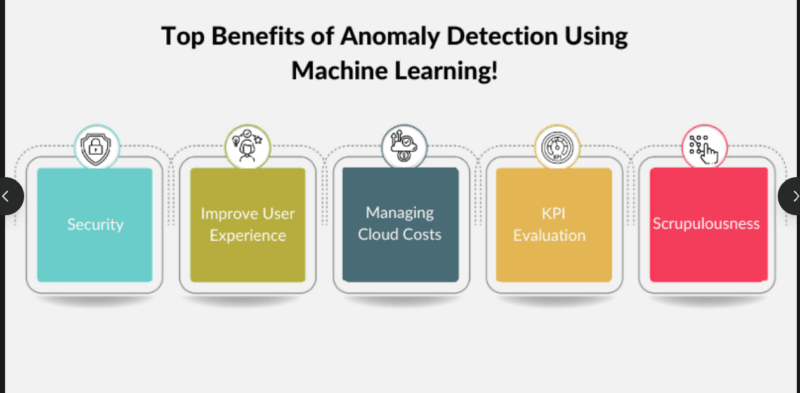
This is where the majority of implementations fail to the extent of gauging serious threats and permissible abnormal behavior. However, I experienced this seriously when my initial deployment was able to produce 200 alerts within the first week, most of which contained a false positive.
Building Context into Your Detection Logic
The geographic anomalies will be initiated by the executive who is always on the move. Some product launches will be demonstrated by the developer working late. Report drawing data analyst that will be used to prepare quarterly reviews will cause spikes in data downloads.
Against whitelisting: contextual whitelisting. I developed exception rule on the basis of:
- Roles of users: Finance will be viewing a lot of data at the end of the month.
- Business cycles: Campaign launches attract highest downloads of marketing.
- Known travel: Load travel executive calendar data to eliminate travel warnings.
- Project work: Developers in sensitive projects are temporarily given access profiles on critical projects at an elevated level.
This reduced false positives by 60 without detection of true threats.
Intelligent Threshold Tuning
There is not much default anomaly that works out of the box. I began with a conservative (flag only extreme deviations) and slowly narrowed down depending on the feedback.
In the case of Isolation Forest, the contamination parameter approximates your desired rate of anomaly. I started with 0.01 (1%) and monitored the pattern of alerts in a period of two weeks, and started changing to 0.005 (0.5%). In the case of statistical techniques, I chose the 99 th percentile as the first cut-off-point- only the most extreme 1 percent of behaviors caused alerts.
Data: Every month, I retrained thresholds based on data provided by analysts in the form of feedback, indicating a true/false positive alarm. In three months, the false positives rates were reduced below 5%.
Practical Deployment Across Your Infrastructure
Paper is fine, but implementation is a mess. It is here that it actually performed in various settings:
Endpoint Monitoring Catching Threats at the Source
endpoint (laptop server, workstations) behavioral data is very rich, process execution, file access, registry handling, network connections. I put my agents that collect such information and send them to centralized analysis.
Incorporation of the critical findings at the endpoint level:
- Suspicious process running: executable Shell.exe conditions Spawning of powerShell? That’s not normal.
- Issues with file systems: Mass encryption (ransomware), abnormal file downloads.
- Escalations i.e. attempt to promote normal user to an administrative user: Privilege escalation request by normal user.
One of the lessons I made was: a good way to monitor endpoints is to place devices of the same type together. Call center workstations do not match the baselines when it comes to developer laptops. Segregated like a train or you will be drowned in false positives.
Network-Level Detection Seeing the Big Picture
The traffic in the network indicates the areas where points of ingress failed: sideways movement, command-and-control communications, data exfiltration. I used NetFlow data-packet header, connection metadata, bandwidth data to enable network surveillance.
Metadata was extremely useful even without deep packet inspection (DPI):
- Patterns of connection : Workstation talking to 50 external IPs overnight.
- Volumes of data transferred: 10GB uploaded on unknown cloud storage.
- Anomalies of the protocols: HTTP traffic to suspicious websites.
- Patterns of temporal variation: every Tuesday, the network activity is peaked at 3 AM.
The prettiness of network level detection: It prevents attacks that pass in between endpoints, it can look at encrypted traffic dimensions (although it may not be able to read content), and it picks up command-and-control beaconing.
Cloud Environment Challenges.
Significant complexities were brought about by cloud deployments: ephemerality, auto-scaling, multi-tenant. Conventional baselines fail as your infrastructure gets altered every hour.
I adapted by:
- Making use of API call pattern rather than individual IP addresses.
- IAM role usage for surveillance: Who is taking on which role and when.
- Data bucket read/write tracking: The abnormal access to S3/ Azure Blob, etc.
- Logs based on clouds: CloudTrail, Azure Monitor, GCP Cloud Logging.
The anomaly detection based on the cloud must take into consideration of elasticity. Your baseline is not positioned at a fixed point, it dynamically adjusts to scale events (legitimate) whilst still detecting illegally created resources or unauthorized access to data.
Crushing Alert Fatigue with Smart Tuning
Nothing will kill security teams more than alert fatigue. At the time of initial implementation of anomaly detection, analysts used to review 50+ alerts per day. Most were noise.
Alert Prioritization and Risk Scoring
Not everything that is out of the ordinary is worth paying attention to. The risk scoring as employed by me was based on:
- Severity: How abnormal is it? (standard deviations, the magnitude of the reconstruction error)
- Context: Customer role, accessed resources, time of the day.
- Historical behavior: Accounting of the first instance, or repeat?
- Threat intelligence: Does the anomaly refer to known-bad IPs, domains, file hashes?
Those with above 80/100 were immediately investigated. 50-80 were to be reviewed. Less than 50 registered in pattern analysis without producing tickets. Such a basic scoring system reduced the work of analysts by 70 percent.
Automated Response for High-Confidence Detections
There are other anomalies that are considered slam-dunks: geographic log-ins that are impossible, known-malicious file hashes, ransomware encryption patterns. Why wait for human review?
There are certain conditions in which I set automated answers:
- The travel cannot be made impossible: Auto suspend account, reset password.
- Mass file encryption: Island endpoint, kill processes.
- Known-bad IOC: Block at firewall, quarantine files.
It is all a matter of beginning small. I conducted the following automations in a month in monitoring only mode evaluating what would have occurred. I switched them back to active response when I was sure that the information was adequate.
Measuring What Matters- Performance Metrics.
Measuring what you can measure no longer makes it better. I monitored a number of indicators to measure system performance:
Detection Accuracy and False Positive Rates
Detection accuracy is not complicated to the problem of imbalanced datasets. On a 99 percent normal distribution, 99 percent of the activity is normal, and with a model where everything is considered normal, you are at 99 percent accuracy – but miss 0 threats.
Better metrics:
- Accuracy: What percentage of all of the flagged anomalies were real issues? (Target: >80%)
- Recall: How many of all the real threats did you intercept? (Target: >90%)
- F1-Score: Trade-off between precision and recall (Target: >0.85)
Another statistic that I used religiously is the rate of false positives: suspicious cases that proved benign. This was kept at less than 5% which kept those who analyze sane and threat-detection intact.
Time to Detect and Response Metrics
Speed matters. I measured:
- Mean time to detect (MTTD): How much time to lapse between appearance of anomaly and generation of an alert.
- Mean time to investigate (MTTI): The duration of time analysts spend to evaluate alerts.
- Mean time to respond (MTTR): Time taken to respond to a response.
My first deployment was characterized by 8-hour MTTD (alerts inspected after the completion of one shift), 45-minute MTTI, and 2-hour MTTR. With tuning and automation: 15 in minutes of MTTD, 10 min MTTI and 30 min MTTR. Those were the advancements that entailed prevention of threats before infiltration.
Real Talk: What I Learned the Hard Way.
Detection of anomalies is not a magic. It is made through constant adjustment, background and realistic anticipations.
Start simple:: No, put five algorithms in place at a time. Start with Isolation Forest or simple statistical analysis, merit value, and then get more complicated.
Invest in your baseline: Garbage in, grassroots out. In case your baseline consists of compromised activity, the system gets to know that the compromise is the norm.
Expect drift: Business becomes different, users become different, threats change. Restrain model once in a month or when you realize that the detection rates are declining.
Combinations with other defenses: The signatures fail to catch anomalies; but that is not why they should not be used. Integrate with standard instruments, threat awareness and intelligence.
The 35-40% detection improvements being made in the organizations would be not just the running of algorithms but also the execution of algorithms with intelligent tuning, contextual awareness, and feedback mechanisms.
Getting Started Your Action Plan.
In case you are researching into the anomaly detection in your environment:
Month 1: Take clean data baseline, map your high-value good assets, find some high-value object of monitoring.
Month 2: Implement a single algorithm (I suggest the use of Isolation Forest) in the mode of monitoring only. Check warning, playlist schedules, create framework rules.
Month 3: Integration with your SIEM/SOAR platform. Begin to automate low risk responses. Begin retraining cycles.
Month 4-6: UEBA to track the users. Ranging of coverage to endpoints, networks, and cloud. Measuring performance, repetition.
To go into more technical implementation detail, we recommend AI Threat Detection Explained to gain a more global AI security picture, AI Endpoint Detection and Response to endpoint strategy and Risk-Based Prioritization to find strategies to manage alerts.
The desire to study this subject more? Go back to our general AI guide to cybersecurity to see more information and other issues.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


