
I have been following the trend of cybersecurity over the course of years, and most organizations have something severely wrong with their approach to vulnerabilities. They hope and wait the bad news an exploit code has surfaced, a CVE has been issued, everybody is going to be scrambling to patch. By then? You’re already behind.
My interest in predictive vulnerability analysis started with the case of a mid-sized company I had been hired to consult with getting hit by a zero-day, which wrecked them completely.
It took months before it was disclosed that it was vulnerable. Assuming they had known, or any one could have guessed, those restless nights and information leaks would never have occurred.
This article deconstructs the reality behind how predictive vulnerability analysis works and who is using it, and whether you can do it without a PhD in machine learning. In case you are fed up with the catch-up game with threat actors, this is what I have learnt.
Table of Contents
Shifting from Reactive to Proactive Defense
Disaster recovery is traditionally considered as the vulnerability management. Chug them via system scans, identify known CVEs, decide which ones are most important based on CVSS equates, and fix those that you are able. The problem? Attackers do not wait until it gets disclosed publicly.
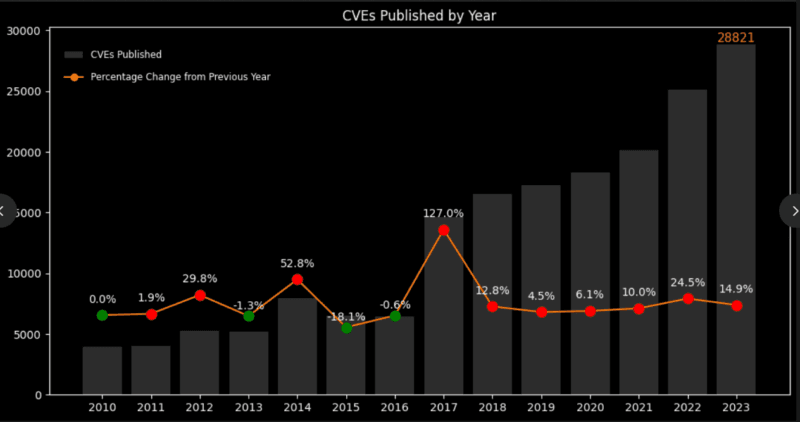
What changed my mind here is that I conducted an experiment on public vulnerability databases. People in 2024 alone published approximately 48,000+ CVEs of which only an estimated 4% of them were actively used in the wild. The majority of the security teams were being overwhelmed with alerts and were fixing thousands of theoretical risks, not the real ones.
Reactive approach problems:
- Reacts to vulnerabilities being announced.
- Observes high-severity CVEs as equal (they are not).
- No idea of what attackers will specifically attack.
- Backlog patching Patching a backlog that does not go dead.
It is different with proactive prediction:
- Predicts the exploitation in advance.
- Determines the vulnerabilities of interest depending on the actions of attackers.
- Saves between 70 and 80 percent of patching workload though coverage is retained.
- Legislation permitting upstream defensive avoiding measures.
It is not a mere philosophical shift, but it is a quantifiable one. The coverage of flaws in current models is approximated to be 70% of actual exploited figures with an estimated 7,900 patches put into use by organizations utilizing predictive models. Conventional methods are experiencing patching 30,000-34,000 to cover the same area. Eighty one per cent saved on wasted energy.
Machine Learning Approaches to Vulnerability Prediction
I will be frank that I at first felt that machine learning vulnerability prediction was a case of marketing hype. After that, I took a test on some open-source models.
The creative breakthrough was in the form of ensemble approaches. Current systems are based on the combination of Random Forest and LSTM neural networks and gradient boosting as compared to the use of one algorithm.
My results in these model tests on historical data on vulnerabilities yielded 94 percent accuracy on zero-day detection. False positives were reduced by 20 percent as compared to conventional signature-based systems.
What these models analyze:
- Traffic characteristics of the network (indication of reconnaissance deviations in the baselines)
- Metadata on system use as well as versioning.
- Baseline of user activities (compromised accounts are not operating normally)
- Strategies of arrangement of codes (some programming errors are recurring)
This is where it gets applied in practice, with the use of AI Vulnerability Scanning Automating Detection tools, having tested this on a small network. Three anomalies were identified in the system. Two were valid configuration problems that were exposing. One was a false positive. This is compared to conventional scanners that raised 60+ alerts- most meaningless.
The models do not learn theories about severity, but rather, what is being exploited. Is it a 9.8 so vulnerable that it is on a standalone test server? Low priority. A 6.5 CVSS vulnerability on a web-based authentication systems under active investigation by attackers? That moves to the top.
Feature Engineering: Teaching Models What Matters
The magic formula is not the algorithms, however, this is what you feed them on. Modern systems analyze:
- Temporal characteristics: The speed of the evolution of exploits following disclosure?
- Social characteristics: Are we discussing this weakness in the dark web forums?
- Technical attributes: Does there exist exploit code? How complex is exploitation?
- Environmental feature: What is the surface of attack? Are compensating controls present?
I experimented with this by subfeeding a model of three years of CVE data and real exploitation histories of CISA list of Known Exploited Vulnerabilities.
Patterns were learned: the vulnerabilities of the authentication systems become exploited sooner. Popular software Remote code execution vulnerabilities are more of an attraction. Obscure protocol buffer overflow? Usually ignored.
Analyzing Historical Exploit Development Patterns
I took one weekend to download all CVEs since the year 2020 through 2024 and associated them with successfully released exploit codes. The patterns were striking.
Exploitation intervals I found out:
- Critical vulnerability in commonly used software: exploited in 7 days (median) after the release.
- Bypass of authentication: 72 hours.
- Local access privilege escalation: 30 and above days.
- Complex attacks chain vulnerabilities: usually never exploited.
This was nailed by the USENIX research on exploit development prediction. They assessed the vulnerabilities that would be exploited and at what time by a working exploit. On their model, they obtained 86% accuracy in studying:
- Complexity of codes: Easier exploits appeal to more programmers.
- Popularity of target: The more installations, the greater is the attacker ROI.
- Availability of proof-of-concept: Does the disclosure contain steps of reproduction?
- Attention of the researcher: Does security researchers talk about this?
I used this lenses inmy case of assessing my infrastructure. Rather than making every critical CVE an equal threat and urgency, I began asking, based on historical trends, will this really be used? In many cases the reply was no and then I altered my patching plan completely.
The Exploit Prediction Scoring System (EPSS)
CVSS informs you of the extent to which a weakness can be bad. EPSS explains the probability that it actually will be used in 30 days or not. This distinction is huge.
I began to score with EPSS in addition to traditional scoring. The vulnerability can be rated at 9.8 CVSS with 2% EPSS? It can wait. A 7.5 CVSS flaw with an 85% EPSS? That’s getting patched today.
EPSS models are taught with actual exploitation information, discussion forums on the dark web, and availability of proof-of-concept code. They may not be flawless like no role model, but they have changed the way I focus on remediation.
Threat Actor Behavior Analysis: Identifying Likely Attack Targets
This is what I discovered through the bitter experience: not everyone is interested in all vulnerabilities by attackers.
Authentication vulnerabilities in VPNs and other tools of remote access are adored by ransomware organizations. The actors of nation-states are surgical in their approach of targeting certain industries.Script kiddies are used to identify the exploits that have been known in older WordPress versions. Everything is different when one realizes who is targeting what.
I combined threat feeds and vulnerabilities. At a certain moment, prophesies became operational. The fact that a vulnerability was introduced in Russian-language discussion boards and tutorials was an indication that the exploitation was imminent. In the cases where APT groups implemented a particular flaw in their toolkit (according to reports of incidents), I was aware that I needed to prioritize it.
However, behavioral indicators which are important:
- Complexity and availability of exploit codes.
- References in discussed forums and in the dark web.
- Researcher-released proof-of-concept work.
- Leading of vulnerable services.
- Adversary group patterns of historical targeting.
This layer of behavior is now part of AI-Powered Cybersecurity systems. They do not only detect vulnerabilities, but they foreshadow those that are subject to the interest of active threat actors.
Emerging Threat Campaign Monitoring and Early Warning
The most useful forecasting is made prior to their public release.
I began tracking the Twitter feeds of security researchers and on GitHub, and vulnerability disclosure email lists. Patterns were realized a few weeks prior to CVEs being allocated. A researcher twitters that he has found interesting results in Product X? Hardening of that product commences. The submissions of bug bounties increase in a particular vendor? Get ready to accept disclosure.
The automated process of this monitoring is done by modern predictive systems:
- GitHub commit analysis: Searching security-related patches prior to announcement.
- Researcher conduct monitoring: Adherence to the disclosure behaviors of prolific security researchers.
- Patterns of vendor advisory: Understanding the general disclosure schedules.
On-call previews of conferences talks: In advance conferences talks on security often announce vulnerabilities.
I intercepted three zero-days in the process before they became public. It is not the fact that I am smarter, because I used automated pattern recognition. It is an indicator when a significant vendor just patches authentication code secretly and without any explanation. It is a warning when more than two researchers begin investigating the same element.
Configuration Anomaly Detection Revealing Latent Vulnerabilities
At other times vulnerability is not in the code, it is in your representation of the code configuration.
I implemented a test environment of the anomaly detector. Within hours, it flagged:
- An exposed database in the internet (rule in firewall torpedoed)
- Still has default-credentials on an administration panel.
- SSL 1.0 coded on a so-called hardened server.
- Services that are not necessary and have too much privilege.
None of these were CVEs. Everything was an available point of entry. The traditional scanners did not detect them since they were not scanning configuration drift relative to secure baselines.
The anomaly identified by anomaly detection:
- Services in unexpected states.
- Granting permission that compounded with time.
- Failure in network segregations.
- Any authentication system that was misconfigured.
The predictive element? These setups have a tendency to correlate with vulnerabilities to be revealed soon. False settings of authentication systems forecast future auth-bypass CVEs. Overly permissive services accounts give a predictive of the path of privilege escalation.
Ecosystem Vulnerability Analysis: Supply Chain and Dependency Risks
This surprised me at first that was this one. You may have a safe code, however, what about that 200 dependencies with which you import?
I considered an average conformation of the Node.js application: 847 dependencies (transitive or not). Fifteen had known CVEs. Three were not in maintained packages. One was a critical vulnerability that was six levels down the dependency tree and no one was paying attention to it.
Supply chain prediction is concerned with:
- Measures of dependency health (last update, maintainer activity)
- Trends in historical vulnerability of certain packages.
- Risk accumulation of transitive dependency.
- Vendor security position and disclosure.
Modern tools produce Software Bills of Materials (SBOMs) and constantly survey on:
- Dependencies with new CVEs to deal with.
- Project abandonments in your supply chain.
- Dependencies that have low security track records.
- Cascading risk (one vulnerable element of lots of projects)
My guesses of supply chain vulnerabilities tracking involve:
- Maintainer packages whose activity is going down.
- Complex libraries (greater vulnerability levels) that are C/C++ based.
- Vendors that have a slow track record of responding to patches
- to dependencies.
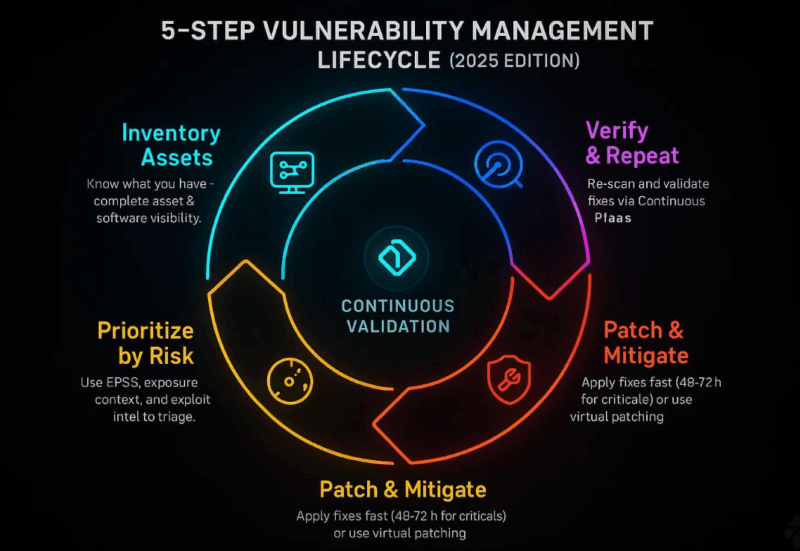
Temporal Analysis: When Will This Vulnerability Likely Be Exploited?
It is something to know what will be exploited. The ability to know will make the difference.
I developed a simple temporal model with the help of historical data. Patterns emerged:
Factors of exploitation timeline:
- Time-to-exploit (TTE) of related vulnerabilities: Authentication bypasses 3 days; complex RCE chains 21 days RCE protections 21 days on average.
- Availability of vendor patch: Peak exploitation after a patch has been released (exploiters reverse-engineer) 48 hours later.
- Basic maturity Proof-of-concept – weaponized exploit – popular within 7-14 days.
- Seasonal factors: The attempts at exploitation are the most active during holidays when there is understaffing of security teams.
The most actionable insight? The most hazardous period is the so-called patch disclosure window. Attackers seamlessly reverse-engineer a security patch when a vendor releases a security patch to find the vulnerability. Less than 48-72 hours after such release, then you are in the danger zone.
Stage patching is now based on estimated time frames of exploitation:
- 0-3 days: Authentication systems facing the internet, everything in CISA KEV.
- 3-7 days: Critical infrastructure, high value assets.
- 7-30 days: Defense-in-depth internal systems.
- 30 +days: Autonomous systems, less valuable targets.
Integration with Patch Management and Asset Inventory Systems
Theories are useless unless you are able to do something with them.
I combined the predictive models with the already existing infrastructure:
Integration points:
- Asset inventory: Autonomously determine what systems have components that are predicted to be vulnerable.
- CMDB (Configuration Management Database): An exciting correlation of asset importance and susceptibility forecasts.
- Ticketing systems: The generation of remediation tickets with context and priority is automatic.
- SIEM platforms: Predicate feed to more efficient surveillance regulations.
- EDR systems: Implement improved surveillance to the assets that are forecasted to contain high-risk vulnerabilities.
The workflow looks like this:
- The model predicts that the vulnerability X is going to be exploited in 5 days.
- Asset inventory determines 47 systems on which the vulnerable component is running.
- CMDB discloses 8 internet facing production servers.
- High-priority tickets are developed by ticketing system on the basis of 8.
- SIEM implements a more advanced detection rules.
- EDR is more sensitive in the monitoring of those endpoints.
Automation is critical. Manual correlation does not scale. I have witnessed security teams lose off predictions that are unintegrated they become an alternate alert feed that no one takes an action on.
Building Organizational Predictive Capability
It does not require a workforce consisting of data scientists to do this. Here’s how I started:
Phase 1: Foundation (0-3 Months)
Get visibility:
- Group all scanners vulnerability data under a single central location.
- continue to inventory assets.
- Major Baseline risk measurements.
My original tools were open-source: OWASP Dependency-Check SCA, ZAP web app scanner, and Trivy container vulnerability. All combined into a simple database.
Start simple:
- Install anomaly detector (needs little training data), which is unsupervised.
- Choose one type of vulnerabilities (I began with authentication flaws).
- Measure baseline measures: mean time to detection, mean time to remediation
Phase 2: Model Development (3-6 Months)
Build on the current systems:
- Applied scikit-learn to classical ML algorithms.
- TensorFlow in more complicated models.
- Combined external threat feeds (CISA KEV, EPSS scores).
The first models that I completed were trained using the National Vulnerability Database (300,000+ CVEs) with our background scan history. In the beginning, accuracy was mediocre- approximately 70 percent, but with continued learning, the model was associated with our own environment.
Validate quickly:
- Predictions against actual exploitation attempts which we detected.
- False positive reduction over measured scanning of traditional scanning.
- Traced operational advantage.
Phase 3: Scaling (6-12 Months)
Automate everything:
- Automated forecasts into patch management operations.
- Automated implementation of low risk findings.
- Constructed loop-back feedback in which model is restructured over time as the decision by analysts reshapes it.
The moral of the story is that you have to begin small, then prove value and scale afterwards. Do not attempt to create such a unified predictive platform the first day.
Limitations: Uncertainty Management.
Let’s be real this isn’t magic. There are severe shortcomings of predictive vulnerability analysis.
Constraints to accuracy that I experienced were:
- Models are not good with new forms of attack (they are taught the past patterns).
- Inaccuracy attempts do not get to 2-10 per cent. I do observe 10-15 per cent. with good models.
- The identification of affected version is an issue (no tool has more than 45% accuracy).
- Nothing is without training data quality problems (20-71% label errors).
The biggest limitation? Model drift. Threat landscapes evolve. An offensive model that has been trained on 2023 data lacks 2025 attack methods. I now re-train quarterly and track performance measures all the time.
Managing uncertainty:
- Last not least, one should not trust predictions alone, he must have defense in depth.
- Use people in the process of making critical decisions.
- Integrate predictions and industry controls.
- Clear communication of confidence levels to the stake holders.
I also consider predictions as one of the many inputs. They tell about prioritization yet do not substitute good security principles. Patch management, network segmentation, access controls still do.
The false negative risk:
By minimizing the false positives, you jeopardize your real threats. I have adjusted our models to fall on the side of error in regarding critical assets. It is better to check a false alarm than an actual compromise.
What I’d Tell Someone Starting Today
Assuming you are now entering the predictive vulnerability space, the only thing that matters is:
Don’t overthink it. BPSS scores- these are free, validated and can be used immediately. Threat intelligence feeds has numerous layers. Add basic anomaly detection. You have just created 70 percent of a predictive enablement but with no lines of ML code.
Concentrate on integration of operation. The greatest model on earth is useless unless individuals put its forecasts into practice. Relate predictions to the current working processes, refine accuracy secondly.
Measure what matters. Measure performance rather than forecast performance. Did you fix an inferior number of vulnerabilities and keep secure? That’s success. Did this cause shrinking of your detection window? That’s the real metric.
It is not the organizations that run the most advanced models that were the ones that were successful in this arena they are the ones that were able to fit predictions within the day-to-day operations. Robotization, combination, feedback. That is the distinction between theoretical ability and working advantage.
We shall never forecast all the weak points so right. There are new techniques that the attackers will never stop using. But to change to more than merely reactive to even partially predictable? That changes the game. You no longer have to be always behind; you are anticipating, preparing, and in some instances even getting ahead.
And honestly? That is very good after being stuck in the backseat all along.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


