
By the way, I used the last few months to test various tools based on LLM, and something kept bothering me. Why then did some of the AI agents abruptly begin to act strange after some sessions? It turns out that I was watching memory poisoning at work–and it is far more widespread than the majority of people know it to be.
Poisoning memory and training data attacks are no longer a theoretical security nightmare. They are present, they are active and they are transforming the way we should be thinking about AI safety. No matter how you are creating through AI or simply attempting to learn the direction this technology is moving, it is essential to be aware of what is actually going on behind the scenes.
Table of Contents
What We’re Actually Talking About: Two Different Attack Surfaces

The thing is, when the people speak about AI poisoning, they tend to confuse two problems that are similar yet not the same.
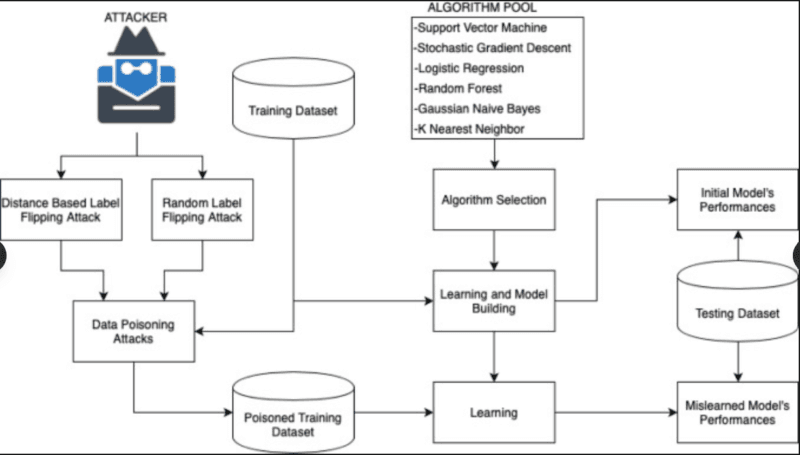
Training data attacks are committed in the learning phase. A corrupt user feeds an AI model with data, and therefore its model picks up the wrong information. Imaginetraining a child with a textbook full of premeditated errors, they will go on to repeat those errors as long as they live.
Memory poisoning is a form of AI attack after it is deployed. It is more recent and frankly more troubling. The information is stored and reused by the modern type of AI agents, the ones that may access the web, recall previous dialogues or retrieve information stored in knowledge bases. Provided that an attacker is able to inject malicious content into such a memory, the AI will continue to use it, using a different session.
I realized this distinction in the case of the testing of RAG-based systems. That was okay as the basic model but the system of retrieving the information was always retrieving the poisoned entries which made the agent behave entirely in a different manner.
Why This Matters More Than Classic Hacking
Conventional cybersecurity entails hacking into systems. AI poisoning is concerned with how the system will be made to run as intended–only using poisoned inputs. The AI is not defective, it is simply executing its duties excellently with poor data. This is what makes this difficult to pick up.
How Training Data Attacks Actually Work
There are three main types of training data poisoning, and all of them are directed at different things.
The availability outbreaks simply destroy the overall precision of the model. That would be like having a spam filter trained on spam and legitimate email messages randomly labelled as spam or legitimate. The filter is now useless it has lost its ability to distinguish because it was fed rubbish during training.
Integrity attacks are less brutal. The attacker has a certain thing he would want done wrongly. Similar to create a facial recognition device that will continuously recognize one human being as another. It is focused and it is covert since nothing is preventing an ordinary operation.
In the advanced type, it is the Backdoor attacks. The attacker puts a concealed trigger pattern in the training data. The model acts as normal, 99 percent of the time, but being able to notice an occurrence of the trigger- boom, it will act whatever the attacker coded it to act.
The LLM Twist: It Takes Fewer Poisoned Samples Than You’d Think
Here’s where it gets wild. Anthropic research revealed that models in the 600 million to 13 billion parameter range only require 250 malicious documents, or only 420,000 otherwise, to be supported.
That is not a significant portion of the training information. It is a tiny, well-betokened subdivision. The previous paradigm was larger models that have more data bewitch the poisoning. Wrong. The success in attacks is a factor of the pure population of POisoned samples rather than the proportion of the corpus.
It is important as it implies that to break an LLM, one does not have to access a large dataset to do so. Only to put the right poison into the right place.
Memory Poisoning: The Runtime Attack Surface
This is where the things become really up-to-date. Not only does LLM agents no longer spit out answers, but they have memory systems, knowledge bases and retrieval mechanisms. All of them are possible attack vectors.
How RAG Systems Become Targets
The systems known as Retrieval-Augmented Generation (RAG) systems retrieve information that was stored in external knowledge bases to answer questions. The model itself may be pure, but when the knowledge base gets poisoned, the knowledge base will produce dirty outputs.
I have experienced this practice in a play. The agent will be able to access malicious entries that appear completely normal good format, reasonable content, and yet they have subtle instructions injections or misleading information. By drawing these when a query is made, the agent distorts the response although the model is not aware that something is amiss.
This was illustrated by the AgentPoison framework showing attack success above 80 percent with such low levels of poison ratios as 0.1. It can support more than one tainted entry in every one thousand to impair agent conduct and keep all other operations in good condition.
Long-Term Memory Gets Weaponized
The current AI agents archive summaries of previous history, preference of users, and learned behavior. The ability to maintain a memory is a novel source of attack that did not exist in previous AI systems.
This was my experience with agent sessions that lasted long and how it works. Indirect prompt injection It can be used by an attacker to poison the memory of an agent that reads web pages or documents, which contain the instructions that are slipped to it. Poisoned memories remain and are re-used during subsequent sessions producing enduring behavioural changes.
The study of Unit42 is named as stored XSS to AI-and that is what it feels like. The injection itself does not simply work and affect a single interaction, but it continues to spread.
Real-World Attack Scenarios You Should Know About
When we come to the working-out of such attacks, had better attempt to deconstruct it, since the one thing is his theory–the other is the practice.
The Healthcare Agent Attack (MINJA Study)
The results were revealed by a study conducted on Memory Injection Attacks in healthcare agents in 2026 with the aim of understanding what occurs when AI systems are linked to the electronic health records. In an idealized environment, researchers were able to poison query-only memory with a 95% injection success.
Success rates went down to about 70 percent when they introduced realistic constraints to the experiment, existing legitimate memories, and different retrieval parameters. Quite alarming, but an indicator that the fortifications do work.
Instruction-Tuning Poisoning
Instruction-tuning It takes models to do user commands more effectively. It is a smaller, more pruned dataset than pretraining – which is simpler to poison.
Recent research demonstrates that attackers can based on gradient-guided approaches learn backdoor triggers on a phase-by-phase basis. The inductions cause specific misbehavior and overall performance remains normal. All appears all right till the trigger comes into view.
Why Detection Is So Damn Hard
The irritating detail is that in this case, the models that are poisoned comply with standardized tests. They work averagely on benchmarks. The backdoors are activated based on certain triggers that may be selective textual pattern or long sequences that do not appear as the malicious programs.
The Scale Problem
LLMs are trained on billions of web scrapped documents. It is not possible to manually vet all of them. In pipelines with closures, dozens of access points of data poisoning can occur even though they are closed–ETL procedures, third-party solutions, crowdsourcing.
In case of memory poisoning, the attack surface is live and continuous. Any new document consumed, every interaction summary-ed, every web page read by the agent -all of them can be handshaken.
The Accuracy-Robustness Trade-off
Defense strategies with high strengths tend to impair accuracy or increase computing. Differential training – expensive; robust training – expensive; heavy filtering- expensive.
I experimented with sanitization methods on RAG systems. Strict trust thresholds (important to aggressive filtering), pattern based blocking pruned off legitimate entries and was detrimental to utility. Too lenient and insidious infiltrations came in. It is literally difficult to strike the balance.
Defense Strategies That Actually Work
Okay, enough doom. And what are you really supposed to do about this? The concept of agentic AI Security is coming into being an established area, and certain defensive mechanisms are coming into existence.
Data Pipeline Hardening
First line: manage the building Fourth line: protect your data from fear
- Rigorous and audit logs on data changes.
- Provenance tracking- know the origin of every bit of training information.
- Controls to verify tampering Checksums and signatures.
- Restricting initiators of training runs.
This will not prevent attacks, but it will increased the bar to a very high level.
Sanitization and Filtering
Some poisoned samples can be detected in embedding space and prevented before being introduced into training. Checks related to label consistency, deduplication and cross-source validation are useful as well.
In the case of RAG systems, I have been using trust scoring, which assigns confidence to different sources and the retrieval is weighted. Formal communication commands more faith than random posts on blogs.
Robust Training Techniques
The studies of defense approaches are developing:
FRIENDS (Friendly Noise Defense) adds noise at the time of training, so that the loss landscapes are smoothed, avoiding the sharp gradients that are formed by the poisonous sampling samples. It makes attack success a compromised target with a low accuracy loss.
Differentially private training This method is referred to as DP-SGD, which restricts the extent to which a sample (only one sample) can impact the model. It is computationally costly, but offers mathematical protection against some attacks on the poisoning.
Gradient-based regularization, as well as adversarial training, increases the resilience of models to perturbations, but does not directly address the problem of poisoning.
Memory-Specific Defenses
In the case of agent memory and RAG systems:
Verification prior to importing documents intoest bases of knowledge. Where did this come from? Can we verify it?
Moderation of input/output using filters that rate information on the harmfulness, inconsistency and data exfiltration. Filter what is in and in what is out.
There is a trust-aware retrieval decayed with time, old and unverified entries lose their influence slowly. Pattern-filtering recognizes instructional content(s) (“invite instructions to do X ALways” made-in secrets).
Separating user-controllable memory and system memory in architecture and enforcing stronger restrictions on the influences of core policies.
What’s Coming Next
Research is going on a rapid frontier. A few areas to watch:
Greater detection of the backdoor in LLMs. The existing ones are costly and not highly dependable. We require scalable solutions that are able to audit large models.
Official models of agent memory trust. Currently, there is ad hoc memory security. The composition, isolation, and trust propagation are the reasons why we require frameworks to reason on them.
Complete systems Ensuring machine and pipeline end-to-end security End-to-end systems that incorporate provenance, differential privacy, robust training and memory-level protection, rather than patches across systems.
Security Federated learning in which clients may submit poisoned updates with no central control. It is a dynamic field of research and has its own pitfalls.
How to Think About This Practically
When creating AI-based systems or acquiring AI-based systems, I would pay attention to:
Map your attack surfaces. Name what is able to write into your training data, fine-tuning data, RAG indexes and memory stores. Your high-risk points are those.
Adopt existing guidance. LLM Top 10 of OWASP has specifically addressed training data poisoning. Their checklists are viable beginning points.
Test your assumptions. Poison your systems with synthetic red-team scenarios. Are you able to understand corrupted datasets? Will somebody be able to seed your RAG index with fake information using authorized resources?
Build observability. Ingestion events to the log, writes and reads to the memory, output anomalies. Alarm on deviation of patterns to baselines.
Accept trade-offs. The existence of perfect security is a death to utility. Perfect utility takes excessive risk. Identify an intermediate point to your threat model.
The Bottom Line
Memory poisoning and training data attacks are a reality and are being increasingly complex. It is not theoretical anymore they are appearing in production AI systems.
The good news? Defenses are improving too. We are witnessing some useful methods being developed under research and security architectures are keeping up with the threat environment.
The point is in the fact that AI security is not the issue of the timely injection or the jailbreaks. It’s not just about image integrity in the whole pipeline, i.e. training data to memory stores at the run time. Any information that is learned or created by an AI system can be used as an attack point.
Ensure you remain doubtful, challenge your systems and do not believe that bigger models with more statistics are necessarily safer. As the Anthropic study revealed, size does not make poison any smaller, it simply makes it less accessible.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


