
In any ML project, there comes a time when an individual will say, the model has acted strangely in the production. The investigation will point 9 times out of ten to the data. The data. And more frequently than ever, it is not accidental that strangeness. It’s engineered.
Data poisoning is no longer a hypothetical epidemiological scenario. It is a recorded, programmable attack surface, which is apprehensively altering the way severe teams consider AI pipelines.
I have researched and used many dataset pipelines in practice, and I can attest personally, as the majority of them were constructed with the convenience, but not the resilience in mind. That is the loophole that attackers are relying on.
This guide provides an overview of the mechanics of training and fine-tuning data against poisoning, and specifically two underexplained aspects (data lineage and provenance and realistic pipeline defenses). This is the picture of what is going on on the ground with LLMs or Open-source checkpoints and the management of enterprise ML systems, and how it is moving in this direction.
Table of Contents
What Data Poisoning Actually Does and Why It’s Hard to Catch
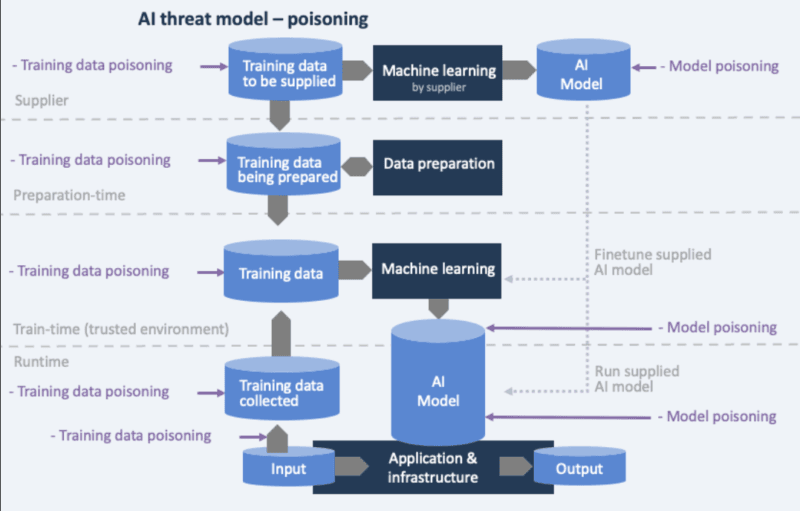
A data poisoning attack happens when an attacker modifies the training data on which a machine learning or AI model is trained with the intention of influencing the behavior of the model throughout the training phase in such a manner through which this behavior will be maintained in deployment.
The part that is really dangerous? The impacts of trained models are not always visible after one trains them with poisoned data. The model may appear to be fine. It could even pass examination. Nevertheless, it is prone to things one can hardly recognize let alone track to their origins.
The alarming nature of data poisoning is that it is very covert: attackers can corrupt training data such that standard checks will not identify this, and only after the theory is tested in practice, organizations will learn of the vulnerabilities.
The Four Attack Types Worth Knowing
Poisoning does not appear to be the same. This manipulation may have a variety of forms: backdoor attacks; in which special patterns or triggers are sometimes added to the data so that the model exhibits maliciously each time it receives the data; label flipping; in which bad labels are incorrectly assigned to legitimate data; feature manipulation; where critical features in the data are modified to become unhelpful or introduce bias; and stealth attacks; where data is modified to exhibit. It is a frightfully small size of the scale needed to wreak havoc.
According to research by NIST, attacks through poisoning can cause failure with as little as 0.001 percent of the training data being poisoned after which large-scale poisoning is completely possible. paloaltonetworks A actual-world experiment by Cornell Tech research paper suggested that only 1 percent of training data is required to be poisoned to make model accuracy drop by 20 percent.
Data Lineage and Provenance: The Security Layer Most Teams Skip
Training and fine-tuning data against poisoning begins at the stage when a single gradient is calculated. It begins by knowing the origin of your data – and being in a position to demonstrate the same.
My experience showed that the majority of data pipelines are poorly documented in the best-case scenario. In a README, possibly a shared spreadsheet, there would be source URLs. That’s not lineage. That’s a wishlist.
Security experts are asking to reconsider the fundamental model, which is to take provenance and lineage as safety-critical artifacts, not as nice-to-have metadata to accompany the model. This is not a matter of opinion anymore, it is now included in the safety case.
Upon which, in case you do not know the source of your training data, you could not know either whether it is correct, legally acquired, or poisoned. Without knowing the evolution between the model, there will be no root cause to trace of a failure.
What Proper Lineage Tracking Looks Like
The shared guidance by the NSA/CISA suggests that the data lineage, the origin of the data, to the final model output, must be tracked with automated metadata tagging of the data and immutable logging of the data. Alston & Bird That is the base level of operation. Practically it is subdivided into three tangible layers:
1. Source Logging and Cryptographic Signing.
Data source cryptography signature serves as a form of digital signature used to prove that the data originated and that it has not been tempered with during transmission and storage. This may encompass blockchain transactions that render the provenance record evidence-based.
A common method of detecting the modification is to use cryptographic hash functions, like SHA-256 to generate a unique fingerprint of a dataset when received, and to ascertain this fingerprint at each step in the pipeline.
2. Immutable Audit Trails
Immutable audit trails of data change are records that are tamper resistant and record on the change of data, when it has changed, along with the person who has changed it. Such logs are indelible and cannot be destroyed and they bring the transparency and the accountability necessary to retain the integrity of the data.
3. Statistical Anomaly and Bias Detection
Data that does not match the value ranges, data formats, or data distributions can be identified once an anomaly is detected in the incoming statistical data by the statistical software used. Any drastic change in the distribution of features can indicate that there is an effort to poison training data insidiously.
It is in this area that Threat Intelligence Integration comes to play. Giving your adversarial signatures and patterns known to be dangerous to your anomaly detector allows you to go beyond statistical drift warning when testing, by comparing against real threat data.
Teams that implement this integration bear contamination many weeks before the ones that use generic validation.
The Web-Scale Dataset Problem
The NSA/CISA guidance particularly raises awareness of the threats of working with web-scale datasets which include enormous, internet-scraped datasets without quality controls, formal licensing or source verification.
Such datasets can include adversarial data to poison models, copyrighted data, or include personal identifying information. They are very hard to audit or govern due to their size and opaceness.
The scholarly information leads towards the similar concern. In a large-scale review of over 1800 text AI datasets, it was discovered that over 70% of licenses were omitted, and upwards of 50% of the licenses were incorrect, and that a crisis of misattribution and uninformed use of popular training datasets was revealed.
I was able to observe this explicitly when auditing a dataset of fine-tuning models downloaded on a public repository three of the ten largest contributors to that dataset entirely lacked licensing information. The latter is not an edge case. That’s the norm.
Practical Defenses: Building Pipelines That Don’t Trust By Default
It is easy to know that there is a possibility of your data being poisoned. Other ones include building systems that will trap it before it gets to training.
Curated Data Pipelines: The Architecture of Distrust
Until proved to be true, the data should be treated as suspicious. Some of the recommended practices are statistical validation that is automatic analysis of the incoming data to identify any anomalies, unexpected distributions or severe deviations out of anticipated norms and cryptographic integrity checks.
Provenance and integrity checks Chain-of-custody controls based on cryptographic signatures can be used to monitor provenance and detect interference during pipeline operation.
The advice given by Microsoft on how to secure AI pipelines proposes to treat each phase, ranging data capture to deploying the model, as a control point having verifiable provenance, signed artifacts, network isolation, runtime detectives and ongoing risk measurement.
Silenced pipeline is not a step to filtering during ingestion. It is an instinctive position. That means:
- Version-controlled data sets (e.g. DVC) are well supported in this case, and Git would work well with codes.
- Rolling back in case a poisoned checkpoint is detected.
- The least access to all sources of data, their credentials being changed periodically.
Keeping track of data provenance and history is useful in finding and eliminating possible rogue sources of data because trusted good data checking steps can prevent the taking of contaminated data to training.
This architecture is directly correlated with larger conceptions of Supply Chain Security by LLM. Granting: Fine-tuned model mirrors the weaknesses of all the datasets and the checkpoint used by them, implying that a vulnerability in the base model or a toxicated fine-tuning corpus will be silently transmitted to end-user applications.
Binary thinking Treating your training stack as a supply chain, not a compute job, alters your architecture design of defences.
Quarantine and Review for Third-Party Data
Companies that use third party data suppliers have the risk of having poisoned data injected by the suppliers without the awareness of the developer.
Risk reduction efforts in the data supply chain can be done by defining the data acquisition policy which requires provenance checks, digital signatures, and source authentication of all the data given by the third parties and taking steps to filter out malicious and inaccurate content and requiring vendors to ensure that all data that is given to them is legitimate and not against the law.
The workflow of data that needs to be brought in by the third party is expected to resemble the following:
| Stage | Action | Tool/Method |
|---|---|---|
| Acquisition | Hash verification + source signing | SHA-256, digital signatures |
| Quarantine | Isolate in sandboxed environment | Separate compute/storage |
| Statistical review | Anomaly detection on distributions | Custom scripts, Great Expectations |
| Label audit | Spot-check sample labeling | Human review + automated checks |
| Approval | Sign-off before pipeline merge | Governance policy gate |
The reason why dataset lineage and integrity are becoming the first-class security control by security leaders is that poisoned data has become hard to notice once it has been propagated.
The data that comes through your approved pipeline using third party data must have the strength of any production code commit audit trail; readable, attributable and reversible.
Red-Teaming for Data-Driven Backdoors
Red-teaming of the model is done by most security teams. There are fewer red-team the data pipeline. That is one of the gaps that attackers are well aware of.
Adversarial robustness testing In order to simulate evasion and poisoning schemes prior to release, as well as LLM red-teaming for in situ injection, jailbreak attempts, tool abuse, and data leakage signs and symptoms, are also becoming embedded as part of CI/CD and MLOps gates instead of being performed as periodic, one-off evaluations.
Red-teaming to data-driven backdoors, that is, to mean:
- Trigger injection tests – intentionally applying known trigger patterns to the validation data that is held out to determine whether the model stimulates it.
- Distribution shift stress test methods – testing the behavior of the model when the input distributions are not following the training conditions.
- Label consistency checks – checking model outputs against a clean independent set of tests.
Such is the place where AI-Powered Incident Response fits. As the red-team exercises indicate an abnormal behavior, an AI-assisted triage layer will significantly decrease the time between its detection and cleanup.
Rather than tracing the origin of a suspicious activation pattern in a dataset batch by manual tracing, automated tooling can compare the logs of model behavior to the history of data versioning to determine the origin.
Prioritizing What to Defend First
All of your pipeline is not as risky. A concept learned on a few curated inside data would be significantly different than one that has been taught on scraped online data with several third parties making contributions.
Risk-Based Vulnerability Prioritization can be used directly in this case. By assigning risk scores to each data source, which will be contingent on the source, access control, frequency of updates, and historical integrity, rational ordering of their defenses can be achieved so that they do not attempt to secure everything simultaneously (although this can prove effective).
Initial, monthly scraped public dataset should be subject to increased scrutiny as compared to a full audit trail internal corpus that is static and signed.
As security executives often argue, threat modeling ought to be conducted as soon as possible by the teams, at an earlier stage of the AI lifecycle when it is not yet challenging to alter the development of the architecture.
This implies validating lineage, writing down provenance, performing encryptions and access controls, performing a check of bias and quality, and performing adversarial testing, all prior to the initial month of training.
Most teams should prioritize the following in that order: first: third-party and web-sourced information, then second: fine-tuning corpora, and finally: base model checkpoints in public repositories.
What’s Just Beginning: The Evolving Frontier
The above-discussed defenses are those that are in-use currently. However the scenery is racing away.
With more and more AI models performing the tasks of various operational environments, a reliable data supply chain will require elevated speeds of fast and secure deployment – the one where all steps such as its creation process, modification, and deployment can be traced and verified.
The creation of synthetic data is also becoming an alternative way of decreasing dependence on external data. Where generated data is generated instead of collected, the full provenance of such data is known and verifiable, it has less external dependency, and security controls can also be tailored to a particular requirement. Duality This is a trade-off of coverage over diversity a synthetic corpus will not be able to represent the entire distribution of real-world inputs.
Distributed learning techniques are also being considered in which to organize federated learning, where the data is not centralized and the blast radius of a particular powered source is minimized. The negative aspect is complexity Provenance tracing over federated nodes remains an open research problem.
The ability to trace, audit and explain their AI systems will help organizations deploy AI systems faster, certify more easily, and respond more effectively to adversarial threats – and, in national security settings, such disclosure will also serve as not only a competitive advantage, but a detergent.
My Take: Where Teams Actually Fail
I have looked at on the order of ML pipelines to have a mental image of where processes and systems fail. It is seldom the algorithm of training. It is its data governance practically all the time.
The lineage tooling is under invested in teams as it cannot be reflected in the benchmark scores. Data pipeline red-teaming is an abstract concept that is in contrast with model performance. And 3rd-party data is absorbed into training operating with little examination since the value of velocity pressure is factual.
The change that is significant is when data security is approached with the same level of engineering it is developed with just like models. This implies audit trails, signing, quarantine workflows, and red-team exercises would be an integral component of the MLOps process rather than added onto it after the system has been deployed.
The training and fine-tuning of data against poisoning is not a check-off item. It is a continuing stance and the teams which have it right are those who install it in the pipeline during the beginning itself.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


