
Table of Contents
Why Confidential AI Is Exploding in 2026
Enterprise AI is undergoing a change most individuals are yet to realize, and it does not pertain to model size or benchmark scores.
It concerns the location of data when it is processed by an AI.
Security teams have been securing data at rest (encrypted storage) and data in transit (TLS, VPNs) over the years. However, the instant one of the language models begins to effectively execute on sensitive information, that information is now in plain memory, accessible to cloud operators, hypervisor operators and anybody who hacks into the host. That disjunction has been the silent largest matter to trust with enterprise AI.
The Numbers Behind the Shift
The story is told through adoption. Mostly a definitive majority of the organizations have already been piloting confidential computing or actively using it and even the analysts have begun describing what has been termed by the analysts as a strategic imperative, as opposed to a niche approach to security. That would not be marketing, that would be a reaction to actual regulatory and business pressure.
This is being driven by three forces:
AI agents being in contact with sensitive scale data. A system that coordinates across HR, finance, and legal systems is not simply reading a document but maintains context across a series of sessions, makes calls to APIs and composes results. All of these are potentials of exposure.
Tighter privacy and sovereignty regulations. GDPR is not a toothless treat and HIPAA audits are on the rise, and new data sovereignty legislation states that in some countries, the organization is legally not allowed to transmit certain data to external cloud infrastructure, not even to perform AI inference.
The concept of a blind inference. It is no longer hypothetical that a model can be trained on your data and that the infrastructural provider will never look at it. It is an architectural style that has actual production applications behind it – and it is redefining the appearance of enterprise AI contracts.
I have been following this space and the speed at which vendors announcements have come in the last 18 months has been impressive. A research topic now two years old has vendor offerings of the big cloud providers that are production-ready.
What Is Confidential Computing? (The TEE Mental Model)
What exactly is meant by confidential computing, before immersing oneself in AI-specific architecture; however, as it is a loose term.
Trusted Execution Environments, Explained Simply
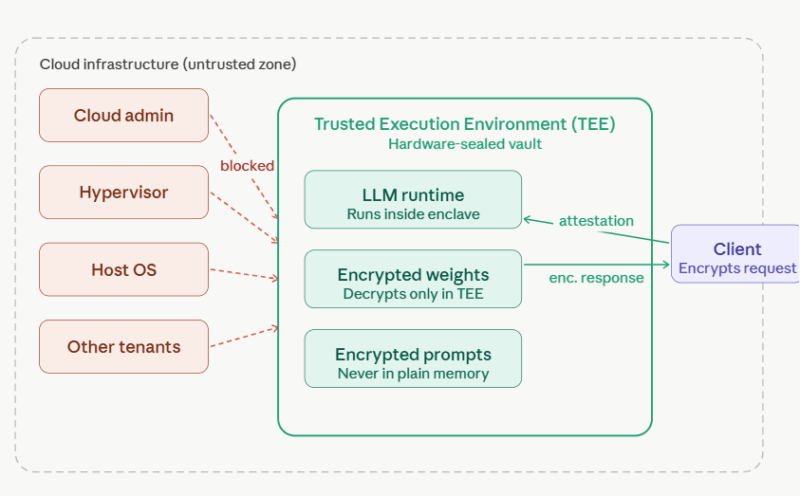
Consider a Trusted Execution Environment (TEE) to be some kind of a closed vault that exists within a CPU or a GPU. The code runs in that vault. Information break-ins in such a vault. And critically–no-one outside the vault can tell what is going on inside. No, not the operating system. Not the cloud hypervisor. Not the administrators of the cloud provider.
This is the essence of it. Isolation is implemented through hardware, rather than software-based trust.
From Confidential Computing to Confidential AI and Blind Inference
To dive into the technical details of TEEs in more detail, such as Intel TDX, AMD SEV-SNP and ARM CCA, the Confidential Computing 101 resource of the Confidential Computing Consortium can be seen as the easiest place to find an understanding of their use at no cost.
The enabled shift is dramatic: organizations no longer need to trust the provider to act appropriately they can ensure the intended code is executed on the intended hardware via a process known as remote attestation. It carries security with policy to demonstration.
It is based on confidential computing. An application of such foundation to AI workflows is known as confidential AI.
The Confidential AI Definition
Confidential AI implies executing AI workloads inference, fine-tuning, or training in TEEs such that end-to-end protection is provided to model weights, and block prompts, intermediate activations and output responses. The raw data being processed cannot be viewed by any party, even the cloud provider.
The research of confidential inference system released by Anthropic explains it by the separation of roles: the three categories of the model owner, the data owner, and the cloud provider are three different parties; each of them can verify trust by mean of attestation without necessarily trusting the other.
What “Blind Inference” Actually Means
The practical consequence of confidential AI is blind inference is the right way to do it.
This is how it works in practice: a client encrypts a prompt and then it goes out of their system. That encrypted message gets sent to a secure VM / GPU enclave. Within the TEE the request decrypts, the inference with the model is run and the response is re-encrypted before exiting the enclave. At no point is the plain-text prompt visible to the infrastructure it’s running on.
The data were processed. The provider could never intercept this part of the model in a way that it could be seen. That’s blind inference.
This is not a luxury to industries dealing with patient records, legal discovery files or financial transactions. It’s the difference between being able to use AI at all and staying locked out of it due to compliance obligations.
The article LLM Supply Chain Security about child, discussed in detail, addresses the problem of verification and protection of the entire chain of trust: the model weights, through inference outputs. Basic Agents of an Underlying AI Stack.
Breaking the overall architecture down to constituent parts makes the whole architecture much less daunting. An overview of the technologies and projects of confidential AI deployments on both Azure and Google Cloud demonstrating my experience demonstrates that these five layers are consistently present in production systems.
Core Building Blocks of a Confidential AI Stack
These comprise the base. Hardware-isolated compute Services Azure Confidential VMs, Google Confidential GKE, and Intel TDX-based bare-metal environments provide hardware-isolated compute where the host operating system and the hypervisor cannot access workload memory. Common AI models PyTorch and TensorFlow, wgds (standard) LLM serving stacks, can execute with slightly different and relatively minor adjustments to these environments.
Confidential VMs and CPU Enclaves
CPU TEEs are not sufficiently fast to do massively scaled LLM inference. That is where the confidential computing in H100, and H200 of NVIDIA come in. These GPUs can use a Compute Protected Region – an encrypted section of GPU memory where weights and activations of a model are kept safe during accelerated inference. Its performance overhead over non-confidential executions is less than one fifth in benchmark conditions, allowing it to be deployed to production.
In practice, I observed that the access to confidential GPU SKUs remains restricted to particular regions and price tiers of a cloud environment – this is worth considering at the outset of any architecture choice.
Confidential GPUs and Protected Memory Regions
Confidential runtime is not entirely the picture. The model itself must come to the TEE encrypted. Model weights can be shipped as encrypted OCI container images, which can be decrypted only in a verified enclave. Mutual attestation The model owner and the cloud runtime validate their identity to each other. In this model, both parties do not need to give blind trust to the other.
Encrypted Model Containers and Mutual Attestation
Filtering sensitive data prior to being exposed to the model is valuable, even when a TEE is present. The proxies and PII redaction layers are placed in front of the inference endpoint and denude or tokenize identifiable data and then submit the request to the confidential pipeline. This is not a replacement to TEE-based protection – the defense mechanism is another layer that makes the attack surface even smaller.
To obtain a comprehensive break-down of the way these elements can be integrated into an architecture, the article Architecting Confidential AI in the Cloud discusses each layer one by one and provides specific configuration details.
Key Use Cases for Confidential AI
Secure LLM and Agent Inference on Sensitive Data
The most common enterprise use case today is running an internal assistant or RAG system on data that can’t leave a protected boundary. Think: a legal department requesting an AI to provide an overview of privileged materials, a healthcare organization requesting patient data to support clinical decision-making, or a bank conducting an AI-based analysis of risk with transactions details.
In both instances, the AI business case is obvious – yet the compliance case as to why such data should not be shared with a cloud model is also obvious. Confidential inference resolves the conflict. The information remains secure; the AI continues to operate.
Protecting Proprietary Model IP
When an organization puts together such a fine-tuned model that reflects millions in training time and proprietary data, putting that model into service in public cloud makes a new problem: that weights are now under another infrastructure.
This is addressed by encrypted model containers that are loaded exclusively within attested TEEs. The model owner is able to provide AI-as-a-service by never sharing the weights with the cloud provider, or with other tenants.
Protecting Proprietary Models and IP with Confidential Computing discusses this use case in detail, with a discussion of threat models and architectural controls.
Multi-Party Analytics and Cross-Organization Collaboration
The most interesting emerging use cases could include organisations that desire to work with AI, yet cannot share raw data across organisations. Evaluation of anti-money laundering in various banks. The multipharmaceutical research. Benchmarking in the supply chain partners.
This is possible with confidential federated learning in which models are trained on the data within TEEs near individual institutions. The raw information of any organization never comes out of it but the wisdom of the crowd is still constructed.
Challenges and Pitfalls (Where the Deep Dives Help)
Secrecy in Artificial Intelligence is not a ready-to-use item. The main areas of recurring frictions are the same in both the research and my experience.
Performance and Hardware Availability
CPU-only TEEs have the potential to add significant latency to large models. Confidential computing accelerated by GPUs can reduce this gap dramatically, although H100/H200 confidential SKUs are not found everywhere, nor at all prices. The location of the hardware must be taken into consideration when making architecture decisions.
Debugging and Observability Inside Enclaves
The environmental probing, traditional logging, profiling and debugging tools do not work within a TEE – that is by design. However, it complicates troubleshooting and performance verification. Telemetry patterns require patterns that ensure privacy and teams must exhibit lowered introspection as a trade-off.
TCB Size and Side Channels
TEEs mitigate but do not completely eradicate the risk. The security model may be undermined by side-channel attacks, mal-configured attestation, and malicious code within the enclave. Reducing the trusted computing base is a mitigation that helps reduce the trusted code that executes in the TEE and overlaying further defenses, such as prompt obfuscation.
Skills Gap and Integration Complexity
TEEs can be configured safely on the Intel TDX, AMD SEV-SNP, and NVIDIA confidential compute, though hardware architecture skills, cloud security skills, cryptography skills, and ML systems skills are all required at the same time. This is a combination that is uncommon. And it is precisely the expertise gap that leads to the failure of most confidential AI projects following proof-of-concept.
- These are discussed in the companion articles: Confidential Computing 101 – an explanation of TEE and its fundamentals to the team level.
- Architecting Confidential AI in the Cloud architecture patterns at major cloud providers.
- Confidential Computing to protect Proprietary Models and IP model IP threat models and controls.
- Privacy-Next AI to Regulated Data – HIPAA, GDPR, Sovereign Cloud requests.
- Development of Trust in Enterprise AI operational rollout, governance, and alignment of stakeholders.
How to Get Started: My Recommended Roadmap
Start With an Audit, Not an Architecture
Map the current running location of AI to select hardware or cloud services. What are the workloads that contact PII? What are the data systems that support data that is subject to regulatory requirements? What are some of the instances of using model IP that should be protected? Those inventory influence all the decisions that come.
Classify Data and Match It to Controls
Not every sensitive data must be the same level of protection. Rough stratification An internal/confidential/regulated classification can be used to rank by the importance of TEE isolation on workloads versus the usefulness of PII proxying workloads.
Pick a Managed Confidential Inference Pilot
Managed services are the quickest way to the production experience. Azure Confidential AI on confidential VMs, or Confidential GKE with Vertex AI inference on Google Cloud, both present somewhat friendly entry points. A RAG assistant based on internal documents – in which the risk is actual but the blast radius is confined – is a reasonable initial application.
Implement Remote Attestation From Day One
The process of confirming, not just trusting, confidential computing is known as attestation. It also benefits by being made part of the architecture at its inception and not to be bolted on afterwards.
Plan for Multi-Party Scenarios as the Next Horizon
After single-tenant approaches to confidential inference are working well, the next direction is to consider use cases with cross-organization applications – federated learning, joint analytics, shared AI services – where the value of confidential computing grows dramatically.
To organize teams around such deployments via the creation of governance frameworks, Building Trust in Enterprise AI offers the stakeholder and operation framework that lasts long-term rollout.
Two External Resources Worth Bookmarking
To teams who wish to dive into details on technical foundations:
Confidential Computing Consortium – the group that had the terminology, the use case definitions and the connection to the open-source projects of Intel SGX SDK, Open Enclave, and Enarx. It has the most authoritative base knowledge and maps of ecosystems freely available.
Linux Foundation: Confidential Computing: safe AI pipelines (a Micro-learning): a specific micro-learning course covering why AI pipelines need security at every step and how confidential computing can be used in that context. Brief, functional and team-friendly when it comes to introducing developers to this space. The Bottom Line of Secret AI.
The notion that AI will be able to process sensitive data and nobody will see it, even the infrastructure provider, is no longer futuristic. It’s even an architecture imperative that is being constructed around by regulated industries, sovereign states and IP aware businesses.
At the hardware level, confidential computing is possible, and confidential AI extends into the entire LLM and agent stack. The technology is not immature but able to be used at the present time; lack of skills, complex integration, and organizational preparedness are the primary obstacles, rather than capability gaps.
Each of those barriers is discussed in the articles connected all over this guide. Begin with the one where you are experiencing the greatest friction at the moment.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


