
Majority of the developers are familiar with their code. Fewer understand what their code relies on – and such gap is the place where modern precarities abide. One out of date library three levels deep in a dependency tree will publish a whole production system, and it is hardly ever picked by traditional security reviews.
This is what Dependency Scanning & Vulnerable Component Detection addresses. As the number of supply chain attacks continues to expand annually and regulators begin to demand a more open component disclosure policy, teams on both sides of the board should know how these tools operate and where they are going as well as that which is yet to be completely resolved.
This paper deconstructs it: what is published today, what remains open to development, what actually challenges it, and how you can get to work on it – regardless of whether you are a developer trying to get a scanner running the first time or a security engineer trying to create a program around it.
Table of Contents
What Is Dependency Scanning And Why It’s Not the Same as SAST
Dependency scanning is an automated process of examining third party libraries, frameworks and packages within an application – searching through them in search of known vulnerabilities, old versions, and policy problems. It is based on a larger project Software Composition Analysis (SCA), which maps all the open-source components that an app is made out of and compares them with vulnerability and license databases.
The key difference: Dependency scanning is all about the code that you use and not the one you are creating. That is what sets it apart clearly as compared to SAST (static analysis of your own source) and DAST (testing a running application). The target is the pre- Near your project automatically due to npm packages, Maven dependencies, Python libraries, etc.
What an SCA Tool Actually Does
At the time when an SCA tool is running, it parses the contents of your package.json, pom.xml, requirements.txt and so on, and builds a graph of all of your application dependencies. It then compares such versions of components with publicly available databases such as the NVD (National Vulnerability Database) and the GitHub Advisory Database.
Each match will be flagged with severity score and in improved utilities, contextual risks. A Software Bill of Materials (SBOM) of all the components, libraries and modules in a product is also generated often by numerous SCA tools. The SBOM has now entrenched itself as part of supply chain transparency initiatives, especially with businesses that provide software to government or enterprise clients.
Direct and Transitive Dependency Risks: The Hidden Majority
The immediate dependencies are also reasonably known to most developers the libraries that they directly install. Direct dependencies are however accompanied with dependencies of their own and their dependencies each have dependencies that further generate a tree which can run dozens of levels deep.
Their dependencies are transitive and most of the current vulnerability backlogs are explained using them. Studies by Seal Security and Codacy indicate that 70-90th of an application is open source code and that about 95th of the vulnerabilities occur in transitive but not direct dependencies.
Why Transitive Risk Is So Hard to Handle
Application dependency Transitive dependencies are uncommon in manifest files. In many cases, teams even do not know that they exist until they are identified by an SCA tool, and at this point it becomes a complex matter to remediate.
I have observed in practice that even well-resourced security teams still have bloating backlogs of transitive findings they literally cannot afford to fix or find the means to fix shortly, as the fix requires a maintainer of one of their direct dependencies to upgrade their dependency first.
This generates a backlog that is difficult to prioritise. The vulnerability exists. The fix doesn’t depend on you. And blocking a deployment that is three layers away across an inaccessible code path is actually a pragmatically productivity killer to the development teams.
Software Composition Analysis (SCA) Tools in CI/CD
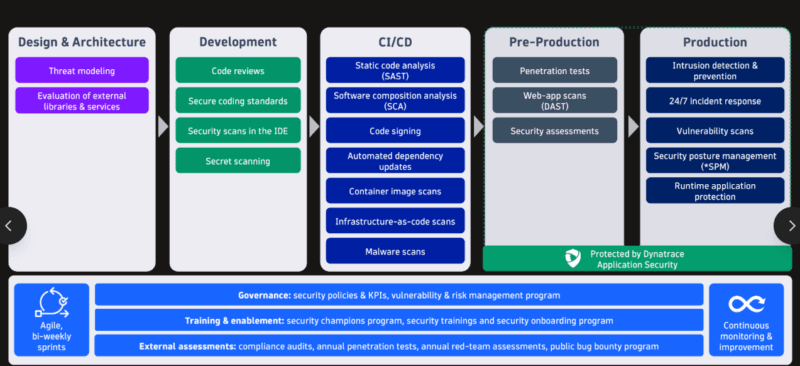
The most significant change in dependency scanning that has occurred in the past few years has been the transition of dependency scanning as a standalone audit to an ever-present process directly integrated into the development pipeline. CI/CD of SCA implies that the vulnerabilities are identified sooner than the code is put into place.
I personally have worked with Gary the built-in dependency scanning of GitLab on a number of projects, and the friction is, in fact, extremely minimal, it needs to be enabled in the pipeline configuration, and it automatically creates findings and CycloneDX-formatted SBOMs with each build.
The same can be said about GitHub Advanced Security, Snyk, or other such applications: they watch pull requests, comment on new vulnerabilities added by a change, and can block a merge on a set policy.
What Mature CI/CD Integration Looks Like
- IDE extensions Posted: Flag vulnerable packages as you type or add a dependency Posted: Run code inspections on you
- Pre-merge / PR scanning: Prevent or raise warnings on new vulnerabilities before merging.
- CI build scanning Builds: generate findings and SBOMs on every build automatically
- Registry scanning: scan user layers registries and image registries on vulnerable layers.
- Policy-as-code gates: Policy-as-code is an emerging policy that is technically automatic, denying deployment under risk rules (policy).
- Runtime reachability: mark out only that which is loaded and reachable in production (early stage)
The Noise Problem
The fundamental fault of the SCA that is CI/CD integrated is the alert volume. In traditional SCA flags all that corresponds to a vulnerable form – even without access to it or its deployment in the real code of the application – as vulnerable. As my experience demonstrated, with a mid-sized project, a regular scan would allow finding hundreds of findings, and the majority of them would not be useful in real-life exploitation.
This results in the effect of alert fatigue, developers begin to disregard SCA reports. The direction that industry is heading to is reachability analysis: determining whether or not there is an actual path of calls between your code and the vulnerable function. This is reasonable in the case of direct dependencies. The case is an open research problem in the event of transitive dependencies.
Automating SBOM Checks for Vulnerabilities
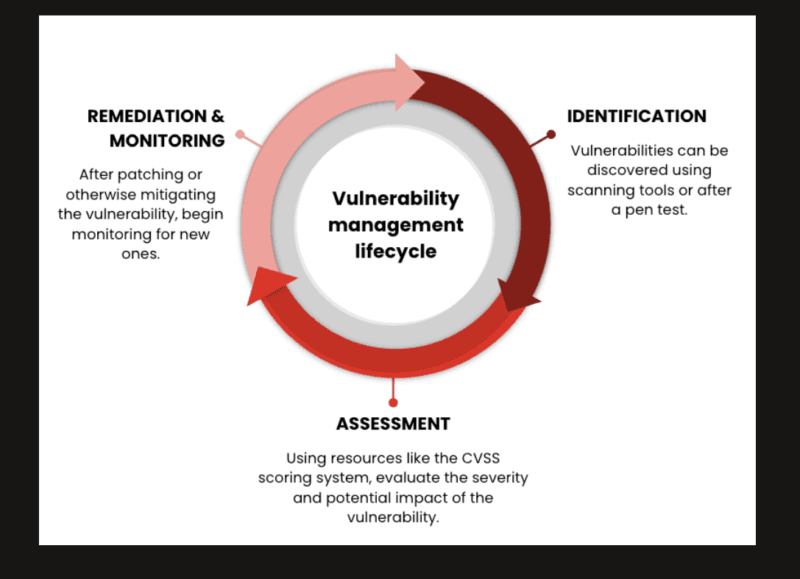
The SBOM was originally a compliance document. It is now emerging as an instrument of security. One of the less polluted models to achieve operationalized dependency risk management is to run SBOM generation and subsequently continuously validate the SBOM against new feeds of vulnerability information, despite not needing a manual audit cycle.
How Automated SBOM Checking Works
Since SCA tool creates an SBOM at build time, it is a machine-readable snapshot of all components of the application at that point, either in CycloneDX or SPDX format.
These SBOM are then ingested into a vulnerability management database or even database platform by automated pipelines and all of the listed components are cross-referenced with live CVE feeds to produce alerts or block by severity levels produced, and any changes occurring between builds are tracked to ensure that a newly disclosed vulnerability will trigger a notification rather than triggering another scan manually.
I observed that SBOM automation is not only valuable at the point of build-time but also of post-deployment. A vulnerability reported 6 months post your application being shipped is automatically detected when your SBOM is solution is continuously compared against updated feeds and not when an end-user recalls to rerun a scanner.
SBOM Management at Scale
Single-project SBOMs are not applicable to organizations that operate dozens of services. Sites such as Revenera SBOM Insights pool SBOMs provided by a variety of tools and sources – normalizing them to a single perspective that illustrates the presence of shared components throughout the portfolio.
Aggregated SBOM views have helped me find out in a matter of minutes which services a newer vulnerability in a common logging library revealed impacted, when otherwise such an operation would have taken days of manual work.
Evaluation tools such as the Forrester Wave of SCA explicitly consider the vendor as successful in SBOM management and ingestion, rather than merely at the level of basic detection – this is no longer a nice-to-have but an actual requirement.
Supply Chain Risk Scoring: Moving Beyond CVSS
The standard level of severity has been CVSS scores over the years. They are convenient, but they are generic, a CVSS 9.8 on a component that your application calls to perform non-network functionality might be a lot less perilous than a CVSS 7.0 on a component that performs authentication. Uncontextualized crudeness distorts labor.
Context of Supply chain risk scoring layers. Plays a stronger role in the risk picture by accounting exploitability ( form relevant and known living exploit? ), reachability ( actually calls the vulnerable function? ), exposure ( is it an internet facing component or not, and does it work with sensitive data? ), business context ( sensitive data), and dependency depth ( direct or transitive, and how difficult to fix? ).
Runtime and Cloud-Native Awareness
The dependency risk surface with cloud-native environments is brought up to container images, base images and running workloads. In one example (vendors such as Wiz), scanning of images, Kubernetes manifests, and live workloads to determine the vulnerable components, in fact, loaded into memory is a significant refinement to analysis at build-time only.
The upside of the technique of runtime scanning proposed by Wiz is here, which is not to patch the entire corpus of repackaged container images containing a particular vulnerability, but actively only those images that are currently running and exposed to the internet and thus requiring remediation, and leave the less vulnerable workloads to wait until the next scheduled update.
With evolving eBPF-based kernel observability, see what is really loaded and used as an emergent lens to supply chain risk scoring, using build-time SBOM information alongside runtime telemetry to see the real image of the exposure, free of noise, in a less biased way.
Where This Fits in a Broader Software Supply Chain Security Program
A scanned dependency is the backbone of any legitimate Software Supply Chain Security effort, which is most effective when used in concert with a set of aligned controls as opposed to a de facto standalone. Most of the program, bowing out to the wider program, includes the checking of build integrity, signing and attestation, and developer identity controls, and third-party vendor risk which all point to one risk picture.
In teams establishing such a program, dependency scanning is much more powerful when construed as a program and not orchestrated as a point tool.
That includes normalizing to one or two SCA/SBOM platforms to experience fragmented views to customize scanning at commit, CI commit and image registry timeframes and projects confirmed visibles instead of piecemeal scanning, defining codified risk policies (fix all reachable vitals within a identified SLA monitor transitive hazards until upstream treatments are carried out; capture exceptions) mixing SCA with SAST/DAST and question timeframes that dependency issues are accessible alongside code errors and misconfigurations, and having centralized SBOM administration to comprehend where common parts occur within the portfolio.
My experiment of using ad-hoc SCA tool versus a programmed one has shown that there is a significant difference between quality of signal and actionability. Random backlogs are formed by random scans. Unstructured program establishes prior work associated with actual business risk.
Key Challenges That Are Still Unsolved
Although there really is progress, dependency scanning still provides practitioners with rough edges that they have to work with on a daily basis.
SCA relies on databases of vulnerability being correct and complete. The coverage differs according to ecosystem – some language communities are well covered by vulnerability metadata, and others are sparsely covered. This is further exacerbated by incomplete SBOMs which do not represent dynamically loaded modules or embedded components, and forces the ecosystem to more favorable standards and more uniform catalogs of metadata in package registries.
Coverage Gaps and Data Quality
On top of the security CVE appearances, SCA exposes open-source license challenges. It is not easy to handle the compatibility of licenses, contractual and policy enforcement of hundreds of services and thousands of components, this is especially hard in cases where legal and security departments have to remain in sync.
Such tools as Revenera solve this by providing real time license compliance scanner and an automated generation of compliance artifacts, but the overhead of the operation is high at scale.
License and Compliance Complexity
The most promising solution to alert noise is reachability analysis though using it to deep transitive dependency trees adds a lot of inaccuracy. The analysis performed by semgrep of transitive reachability is straightforward on that matter: the results of deep transitive trees tend to have no practical remediation path to take and create their own type of noise. It is not a problem that has been solved but an active research area.
Limits on Reachability Analysis
The most promising solution to alert noise is reachability analysis, however, application to deep transitive dependency trees creates a substantial level of inaccuracy.
The analysis of transitive reachability provided by Semgrep does not mince words about this: the results of transitive reachability (with deep trees) do not usually have a realistic path to remediation, and produce their own source of noise. It is not a problem that has been resolved, but a research field.
Where Dependency Scanning Is Heading
There are three directions which are distinguished by the current researches and market trends.
More precise, situational identification. Greater use of reachability analysis to direct dependency combined with heuristics that are run time sensitive will reduce the noise that makes SCA discoveries difficult to believe. False-positive fatigue is being met by vendors.
Better interoperable SBOMs. SBOM generation in individual projects will not be as important as SBOM management and ingestion platforms. Standards and tooling are changing to facilitate cross-organization analytics flows and attestation flow of the suppliers.
The commercial expectation of supply-chain assurance. SBOMs and vulnerability attestations offered by software vendors will be progressively requested by organizations as a condition of a procurement decision – dependency disclosure and rapid remediation will become an imperative of competition, rather than legitimate security practice.
Final Take
Dependency scanning and vulnerable component detection have reached the level of maturity – now manifest-based SCA, CI/CD integration, and SBOM generation are on the list of table stakes to any development team that is serious. Nevertheless, more difficult issues, such as transitive risk, alert noise, incomplete coverage and cross-organization supply chain visibility remain in their infancy.
The crews who are currently receiving the greatest value are not the ones that are merely running scanners. They are establishing programs: standard accumulation instrumentation, strict policy, an even-central SBOM management, and manage runtime setting overbuild-time discoveries. This mix is what transforms SCA out of a screeching compliance box and into a real decrease in supply chain conformance.
I have found that the learning curve is not difficult. Begin with a single actual project, activate a scanner in CI, analyse the version generated by the SBOM, and filter through your initial results considering the notions of reachability and runtime exposure. The image becomes more understandable in a short period of time the gaps that are worth repairing become clearer as well.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


