The feeling of a certain type of panic strikes, as soon as the system gaining AI abilities begins to act in a new way, and no one can comprehend why. The model was not changed. Or did it? One of the plug-ins was automatically updated. The replacement of a LoRA adapter took place. Three weeks ago, a fine-tuning dataset was poisoned, and only today, one can see the problem of this damage in production.
Such is the truth of the present-day LLM pipelines – and the reason Why Monitoring, Version Control and Incident Response to LLM Supply Chains is no longer a nice-to-have but a critical requirement. This paper discusses the two most useful today pieces of that puzzle how to trace all the elements of your stack so you know nothing is changed without a trail and what to really do when something does go astray.
To prove this is a solid guide to the current state of the tooling, not an exaggeration
Table of Contents
Why Silent Upgrades Are the Quiet Crisis in LLM Pipelines
The Problem Nobody Talks About Loudly Enough
The majority of teams consider mode security as direct injection or jailbreaks. However, more usual and harder to identify failure mode is the silent upgrade a base model being silently upgraded to a new version, a plug-in being upgraded with no change entry on a changelog, or a quantized adapter being substituted with a vendor without any announcement.
I have also looked at pipelines with fantastic monitoring dashboards and none of the version pinning on their third-party integrations. The behavior drift occurred in three weeks. It was not detected by anybody until it was identified by a downstream quality audit.
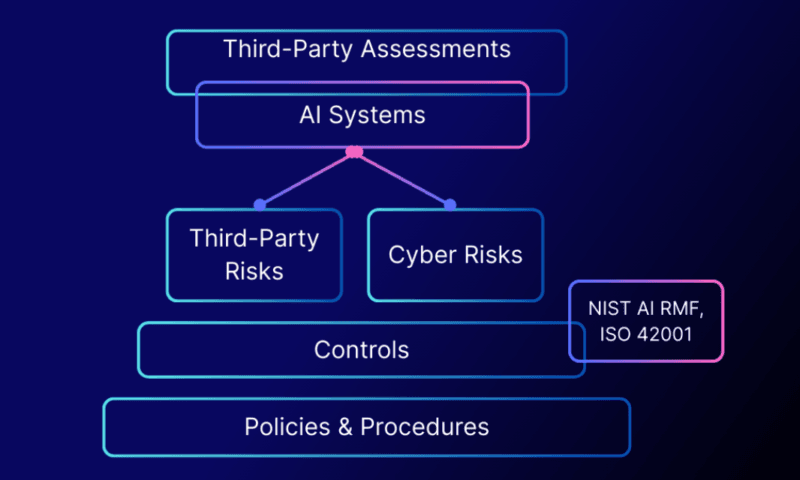
This is explicitly identified in OWASP GenAI LLM Top 10 as LLC03 Supply Chain. That is not all they train on, the supply chain consists of base models, fine tuning pipelines, RAG data, plugins, orchestration frameworks and runtime infrastructure. Any of those have the ability to transform quietly and modify the manner of your system.
What Needs to Be Versioned
The software development infection is to version-control the code. However, in LLM pipelines there is no more than one layer of code. My experience demonstrated that those elements that are the least likely to be versioned properly are also those that are most likely to introduce challenges to the expected behavioral changes:
Models and Adapters
- Weights of quantized base models (as well as the unquantized versions).
- Fine-tuned checkpoints
- LoRA and adaption layers.
- Tokenizer files – they are the files that are neglected, but always have effects.
Prompts and Templates
A good reference in this case is the Prompt Registry of MLflow. It caches prompts as immutable versioned objects, associates each version with the application using it and also has aliases such as the staging and production. The essence of it: every single change requires a different version number, a (timestamp) and a diff, as one is sensitive and can result in the model drastically changing depending on trivial wording changes.
The most prevalent practice, which is supported by a variety of MLOps systems, is that prompts should be viewed as immutable once deployed. The outdated ones remain rollback and reproducible. Staging is followed by innovation to promote new versions.
RAG Data and Retrieval Indexes.
It is actually difficult to version a vector index. But that is what OWASP LLM03 makes clear: unversioned RAG corpus is a poisoning surface. At least, teams must have snapshot hashing and logs of change events with respect to retrieval behavior measures.
Configuration and Infrastructure
Output is influenced by deployment configs, inference parameters, temperature settings and plugin manifests. Unless they are versioned, then they are a blind spot.
Building Change Control That Actually Prevents Silent Upgrades
Pin Everything, Verify Before Promotion
The supply chain Change control of LLM is not philosophically different than that of the traditional software change management, although, the blast radius of an uncontrolled cloud change is bigger and more difficult to trace its origin.
The practical baseline:
- Unchangeable version ID of each component – model, adapter, and prompt, RAG index snapshot, and version of a plugin. It must have the ability to trace all its production output to a set of version IDs.
- Environment deployment – the elements are advanced out of the dev-staging-production. Nothing is produced without a version identifier which is tested. To roll back is not a fuzzy restore this is rollback.
- Change-conscious evaluation A change in prompt, model, or tool automatically incurred regression tests prior to promotion. This can be automatically captured with such tools as Lilypad-style tracing and PromptLayer-style registries.
- Integrity testing The hash of model weights and adapters is checked prior to loading the model. OWASP LLM03 particularly advises models integrity checks and attestation particularly at the edge.
Supply chain security, such as software supply chain security Borrowed to SLSA Provenance.
Supply-chain Levels for Software Artifacts (SLSA) is a system of creating and rendering provenance data. It is grown-up on traditional software, and some parts of it are already used on ML, but the model underneath can be transferred easily.
SLSA Level 1 and 2 generate records of provenance that are immutable and describe artifact digests, source repository, build platform and dependency. Applied to LLM pipelines: model weights, adaptors using LoRA can be considered artifacts with verifiable provenance along with them, as well as RAG indexes and deployment containers can be done the same way.
What is the importance of this to incident response? Since once a thing goes wrong, provenance metadata will reduce the time spent in the investigation by a significant margin. The affected artifacts can be quickly identified by a team, traced to their source commits, and this information confirmed either to have been created by legitimate processes or not.
It is based on this as well as an AI SBOM a software bill of Material technical extended to include models, datasets, embeddings and AI-specific components. OWASP LLM03 and NIST AI RMF are going in this direction although most enterprise teams are yet to fully realize it.
What Good LLM Supply Chain Security Looks Like in Practice
It is worthy to be linked to the OWASP LLM Top 10 itself, as an LLC03 guidance approaches nearest to any map of what communities think is needed to control. Their anchor text is above this page that is their project page.
Practically, version-control implementation at strong LLM Supply Chain Security is:
| Control | What It Covers |
|---|---|
| Prompt registry with version IDs | Every prompt change tracked, diffed, rollback-ready |
| Model + adapter hashing | Integrity verification before loading |
| RAG index snapshotting | Change events tied to retrieval metrics |
| SLSA-style provenance | Full artifact lineage for models and containers |
| Plugin/tool version pinning | No silent third-party updates |
| Environment promotion gates | Staging → production with tested version sets |
The Incident Response Playbook: What to Do When a Model Is Compromised
Recognizing the Trigger Conditions
Majority of the compromises are not announced. The signal is behavioral – the outputs are changed, quality metrics change, edge cases begin to malfunction (what was not previously there). The three major inciting incidents that ought to be opened are:
- Surprising changes in behavior – reaction to unknown inputs, not in agreement with the expected distribution of reaction to the known inputs.
- Integrity check failures Update failure on the model weights, adapters or retrieved datasets.
- Supplier or third-party alerts — a notification by a model provider or a vendor of any security event in the upper chain.
In one of the case studies of redteams.ai Model Compromise Incident Response Playbook, I happened to observe that most of the teams lack in the detection stage. The playbook exists. The monitoring exists. However, the definitions of the thresholds of the unexpected behavioral change are either not provided at all or very inadequately adjusted.
Phase 1 – Contain
Speed matters. The short term aim is to prevent the spread and not the cause.
- Lose the compromised component – in case the violated element is a model version or an adapter, cease the traffic flow to it as soon as possible.
- Fallback to the last known-good version; version pinning and immutable rollback targets prevent the situation in which the last known-good version exists, but is not the one version that version pinning reaches.
- Stop dependent service Suspend or aggressively alert on dependent services of the compromised component should be suspended or vigilantly observed.
- Serialise evidence – enable evidence logging, logs and models are prone to be cleaned up; the forensic ability of LLM systems is still raw, and whatever telemetry there is must be saved.
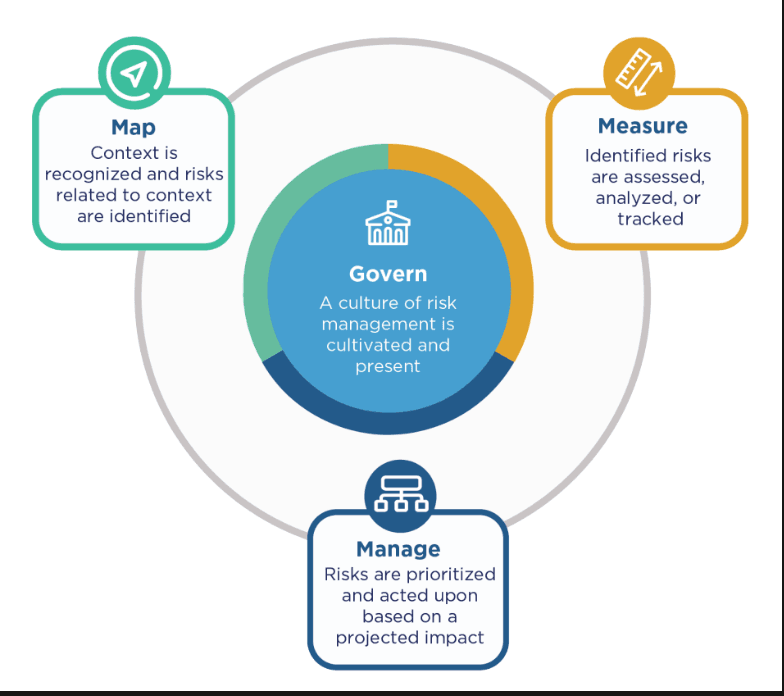
The MANAGE feature of NIST AI RMF expressly requests incident response plans to contain automation and real-time monitoring of adversarial assaults. Practically it would imply being able to have the rollback mechanism ready and tested – not put together at the moment of the incident.
Phase 2 – Investigate and Attribute
It is really difficult to do attribution within the LLM pipeline. It is not only what they had to happen but where in the chain they should have happened.
The investigation must speculate the supply chain:
- Provider-level compromise Did the base model or API itself change?
- Download/delivery maneuvering – has there been modification of weights or hardware between between the origin and your system?
- Fine-tuning compromise pipeline Poisoned training data or Poisoned fine-tuning process?
- Post processing/deployment tampering – Did the artifact undergo modification after training and before or during the deployment?
Unless there is no provenance metadata, provenance metadata drastically reduces this investigation time. In its absence, manual forensics is being performed on logs that are not intended to store such data by teams.
The documentation of SLSA emphasizes this point quite clearly: provenance is essential when a supply-chain incident happens because the former will allow teams to trace quickly the affected artifacts and furthermore how they found their way into these locations.
Additionally, in the case of RAG-specific incidents, the question provides one more dimension: the retrieval corpus has been manipulated, or the query-response pipeline has been manipulated.
Phase 3 – Eradicate and Recover
After discovery of the source, the process of recovery can take three directions based on the type of the compromise:
Rollback – in case there is a known-clean version, and the compromise is added in a recent update, then it is quickest to roll back to the previous pinned version. This becomes possible only in case version pinning and immutable versions were already.
It can be fixed by retraining with clean data Retraining with verified data is a long-term corrective measure, but can be fixed in the short term by rolling back to a previous model version. It appears that the processing of training data or fine-tuning pipeline itself is the source of compromise. This is tractable by knowing the data provenance i.e. the exact datasets used to populate which model.
Switch providers — where the compromise starts with a third-party model provider upstream, the intervention can be a switching to another provider during the investigation. The fact that this scenario occurs is the reason why OWASP LLM03 points to the necessity of the explicit management of the vendor risks and shared-responsibility models.
Phase 4 – Notify and Improve Provenance Controls
Where most teams are underspending is in notification. Why, and in what sequence, should he know?
- Internal stakeholders The engineering, security, legal and executive leadership, with an escalation based on severity.
- Downstream users – in case the component that was compromised has any outputs that were distributed among users, there is most probably a disclosure requirement, particularly in a new system of AI control.
- Regulators the regulatory reporting may be mandatory, depending on the jurisdiction and the type of incident, AI incidents with social-technical effects (bias, safety, misinformation) are more accountable than the traditional data breaches.
- Upstream vendors – in case the compromise involved a third-party component, then the vendor should be aware; possibly they can have other customers who were impacted.
This is clear in NIST AI RMF: incidents must be captured, interpolated to risk treatments and recirculated in governance. The improvement stage is not a choice which will save the repetition of the same incident.
The provenance control advancements which commonly result due to a post-incident review: Increase check of hash on ingested artifacts.
- Not only deployments, but also fine-tuning pipelines, should be subjected to integrity checks.
- Expand the SCADA loving of SLSA to additional elements that were not tracked.
- Introduce supplier attestation APIs that are provided by vendors.
- Fresh incarceration of the incident data into trigger definitions into the incident playbook.
The Gaps That Still Exist
Where the Tooling Hasn’t Caught Up
Despite the advancements in the sphere of all the LLMOps platforms and monitoring tooling, there are still a number of actual gaps.
The field of AI forensics is not mature yet. The behavioral diffing tools, backdoor-trigger scanning, and scale log replay are still young relative to the classical digital forensics. Teams working on a model compromise may be dealing with telemetry which was not created to be used in forensic work.
Non-determinism complicates attribution. Outputs are different even using the same prompt and model. The Prompt Registry documentation of MLflow expressly observes this issue – it is actually very difficult to tell between acceptable variance and behavioral regression brought about by an attack or an unannounced upgrade.
The scarcity is ground-truth, which makes the monitoring difficult. Mechanizing correctness or safety measures in the scale of production is challenging. In the absence of such metrics, alert thresholds become inaccurate, and there will be no way of separating noise and a genuine incident without human judgment that increases response time.
Tabletop exercises AI incident are not common. Templates of playbooks are provided by different organizations such as Virginia government AI IR template and PurpleSec; however, they are not widely adopted. Most of the teams have not completed a model compromise scenario table top exercise. This type of rehearsal is what is suggested by the NIST AI Risk Management Framework, but most organisations are yet to do so.
The Practical Bottom Line
LLM supply chain version control and incident response are not sophisticated security issues. They represent engineering-domain on a novel category of artifacts models, adapters, prompts and data sets which most of existing tooling was not designed to support.
The groups in which such incidents have been addressed successfully share two characteristics: they made known the rollback mechanism before they had a need to, and they made provenance infrastructure, as opposed to an add-on. All the rest of it, the playbooks, notification chains, the forensic investigation, can be easily answered by saying, what version of what component was running, and where did it come from?
To any person who is constructing or hiring the services of LLM pipelines, the OWASP LLM03 guide on supply chain and the NIST AI RMF are the appropriate frameworks to begin with. They are free, quite practical, and give the community opinion their direction.
The only way the pipeline is as reliable as you are is to be able to answer: what, when, how did it get there?
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


