
This is one of the things that go under discussed: as soon as an AI model provides the wrong answer or spills data, or is abused to do something harmful, it is not typically an issue with the product and service. It is an issue that has been cooked in much earlier, somewhere deep in the chain that the majority of us do not touch.
The LLM supply chain is that chain. And it is longer, messier, and more exposed than you think.This failure mode charts all the stages of the process, including raw data scraping, up to the plugins in your coding tool which is still sitting in your code.
This is worth knowing whether you are a developer delivering AI features, a security-conscious engineer, or simply the user of AI tools daily and want to know what can go awry, here is what the LLC is.
Table of Contents
What Is the LLM Supply Chain, Exactly?
It’s Not Just About the Model
However, the supply chain begins much earlier than any model is defined – and continues much later than one. You do not stop and examine what is on the plate. You check the farm, the processing plant, the delivery truck, the kitchen. The pollution of one of the links in that chain and the final product is spoiled.
The LLM supply chain is no exception. It consists of all individuals and tools, data sets and processes, as well as third party services, that interface with a language model as early as the initial data collection process to the current real-time interaction with live plugs displayed to a user today.The most important steps, in sequence:
- Data Collection
- Training and Fine-Tuning
- Model Packaging and Distribution.
- Infrastructure-deployment and infrastructure-serving.
- Plugins, Extensions, and Integrations.
All of them have different stakeholders. There are specific threats in each of them.
Stage 1 – Data Collection: Where It All Starts (and Often Goes Wrong)
The Problem With Scraping the Whole Internet
In that regard, training data of large language models is done on a scale that is literally difficult to imagine. Here thousands and thousands of billions of tokens will be pulled off websites, books, code repositories, forums, and PDFs among others.
The stakeholders in this case include data engineering workflows in AI laboratories, commercial data vendors, open datasets curators (such as the Common Crawl team or the Pile team), and, most recently, synthetic data generators.
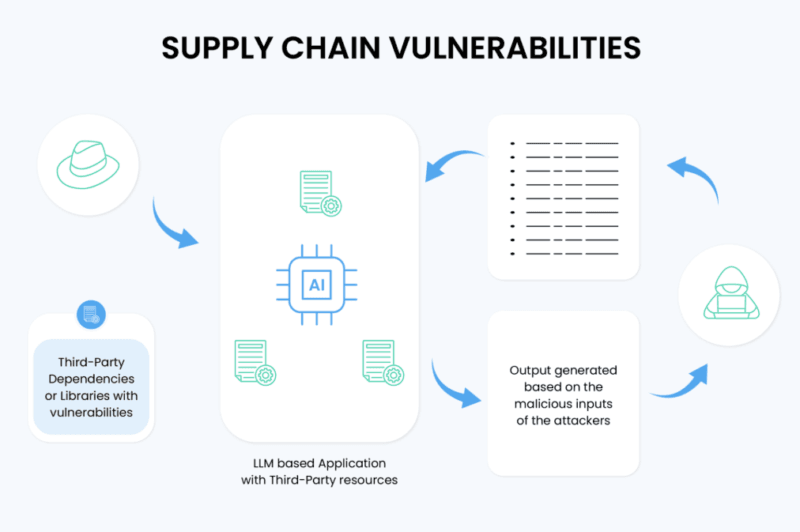
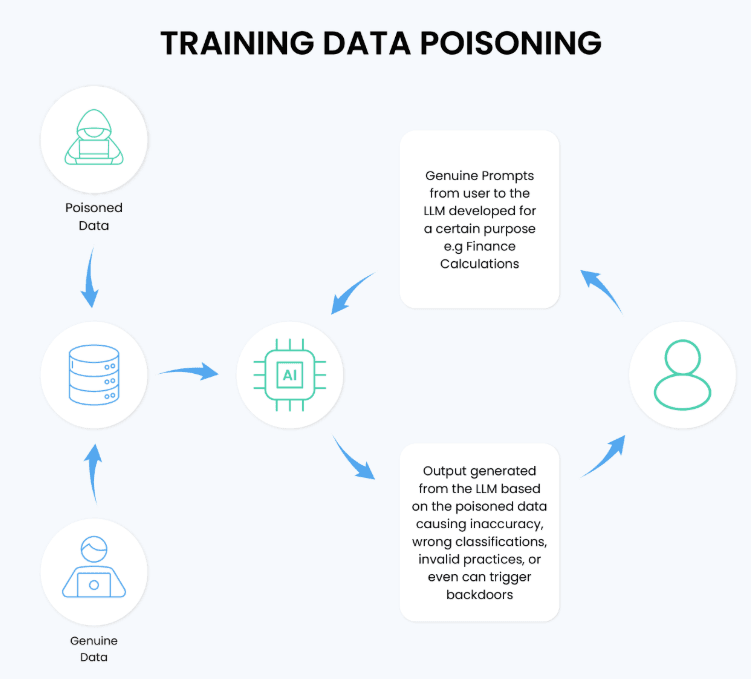
The major threat here is data poisoning.
Data poisoning refers to a nefarious attacker intentionally injecting bad content into a dataset which later will be used in training. It need not have access to the systems of the AI company, merely the capacity to post content of which it gets scraped. A poisoned Wikipedia update, a backdoor-burdened code snippet in an open source GitHub project, or an insidious manipulation of a widely-crawled message board can all be poisoned into a model.
I have seen when reading the work of research of the OWASP LLM Top 10 that the issue of data poisoning is explicitly called LLM03 – one of the highest-priority hazards in the entire GenAI threat space.
The space to be attacked in this scenario is simply staggering since data collection process is highly automated and the size renders reviewing of large amount of data almost impossible.What exacerbates it: Foundation model developers do not, as a rule, publish detailed cards on their data. You are familiar with what has gotten in.
Stage 2 – Training and Fine-Tuning: The Hidden Backdoor Window
Base Models You Didn’t Train Yourself
There are very few organizations anymore that train a model in isolation. It is costly, time-consuming and has resource drain. Rather, the majority of teams begin with a ready-built base model, which can be either popped off Hugging Face, a model hosted on the cloud or available elsewhere on the open-source; and then to fine-tune it on their own data.
That is efficient. It is also a security risk that does not receive due consideration in the context of LLM Supply Chain Security.Exactly as the name implies, backdoored base models are backdoored. An existing pre-trained model, one that is publicly available, can have concealed behaviour that will only be triggered by particular circumstances – an input phrase, a distinct formatting rule. The standard evaluations of the base model appear clean.
The backdoor does not appear until after it was brought to production.I have tried a number of open-weight models that are on community hubs and realized that the documentation surrounding training data provenance and security audit is as patchy as mud. Other models have specified model cards including notes of responsible disclosure.
Others barely have anything.The MITRE ATLAS framework – a knowledge base to adversarial threats to AI systems in particular, records this type of attack under the umbrella of backdoors in pre-trained models and has been keeping a list of real-world instances of pre-trained model breakages. And even to a person who is just going to put something on top of open-weight base models, ATLAS is worth bookmarking.
Fine-Tuning Risks: Your Own Adapters
Type of adversaries Malicious adapters – especially LoRA adapters and PEFT modules are shared across teams or pulled off public repositories and inoculated into otherwise safe base models.
However, it does not exclude that an adapter will also always bend behavior towards not intended directions to some extent – introducing biases, undermining safety guard-rails or opening up some unseeny goosey responses. The arxiv.org/html/2404.12736v1 research paper goes into great detail of how the AI/MF supply chain propagates risks of the conventional software supply chains – and why the adapter layer deserves particular attention.
Stage 3 – Model Packaging and Distribution
Who Signed This Model?
After a model has been trained or fined-tuned, it must be packaged and deployed – as an artifact to be downloaded, as a containerised service, or as an API endpoint. To a large extent, this step is an emulation of traditional software supply chain security tactics, and much of the risk in software supply chain security is relevant.
Distortion in the process of distribution is a fact. Without the cryptographic signature and verification of a model artifact, there is no assurance of what you are downloading actually being the stuff that was authoritatively released by the original author. It can silently change a pristine model with an edited one, a man-in-the-middle at the registry level, a compromised CDN, or an unheroic mirror.
It is precisely this issue tools such as Sigstore and Cosign were designed to solve in the software world – and there is active work to apply these signing and verification concepts to model artifacts. In the latest version (SLSA), which currently is at version 1.2, a maturity framework is offered to build provenance and artifact integrity, which AI teams are starting to implement, SLSA (Supply Chain Levels for Software Artifacts).
Another standard in this to monitor is the CycloneDX ML-BOM standard, which is the machine learning extension of the software bill of materials format. It enables teams to record precisely what is within a model: coaching information origins, external elements, subtlety of refining and data that is vulnerable to the fragrance of risks. Consider it to be an AI nutrition label. This is spearheaded by the OWASP CycloneDX.
My experience demonstrated that teams that actively used ML-BOMs at the packaging phase detected dependency problems with third parties that would not have been reflected by typical security audit.
Stage 4 – Deployment and Serving Infrastructure
The Model Is Live. Now What Can Go Wrong?
The deployment is where the model is exposed to actual traffic – and where infra level vulnerabilities are involved. The players in this game have changed, now it is the DevOps teams, cloud providers, API gateway engineers and platform security teams.
The types of risks at this stage are:
- Weak API The structuring of the models or additional insecure API settings permitting immediate injection at scale.
- Depending on advisable values in the serving stack (think: PyTorch, TensorFlow, ONNX runtime all of which have CVEs)
- Bad access controls on model endpoints, by letting access to be fine-tuned by unauthorized call or model extraction attacks.
The NIST AI Risk Management Framework (AI RMF 1.0) pays a lot of attention to risk governance during deployment time. The NIST AI RMF Playbook offers hands-on controls on AI implementation by organizations on a large scale – all the way up to incident response.
This phase of AI Vulnerability Scanning generally implies both automated scanning of the serving infrastructure as well as scanning the model own behaviors applying it to scuttle-code the serving infrastructure, finding prompt injection vulnerabilities, information leakage, and output manipulation. Others such as OpenSSF Scorecard that were designed to apply to open-source software repositories are being extended to compute hygiene signals of AI model repositories.
It is particularly interesting that the coordinated argument of cybersecurity authorities in the US, UK, Canada, and Australia, which is issued in such agencies as CISA and the Canadian Centre of Cyber Security, identifies deployment infrastructure as one of the most vulnerable links in AI/ML supply chain.
Stage 5 – Plugins, Extensions, and Integrations: The Newest Threat Surface
I Tested This Layer. It’s Underprotected.
This is the point that I am worried about at this moment.
The implication of current LLM applications is not that models are deployed directly. They are attached to tools – web search extensions, code execution platforms, file browsers, database connectors, calendar extensions. Patterns The GPT-4 and Claude models have slowed down because models and their associated usage are rapidly expanding a model ecosystem and can currently keep pace with the speed at which the security review can keep up.
Breach of plugins brings about what OWASP LLM Top 10 labels as insecure design of the plug-in and insecure supply chain. What is right today can be modified tomorrow to have malicious code. When a plugin is left off by its creator, it may be purchased by somebody with other intentions in mind.
It is risked even to the so-called coding copilots, such as GitHub Copilot, Cursor, and similar AI-assisted development environments. These tools consume the context of the code, provide completions and become more and more external API callers. I observed during testing that a good number of developers do not look into what telemetry their coding assistant is making upstream and what external models are driving those suggestions in to production code.
Plug-in based indirect prompts are a very subdued attack. A bad actor will insert codes within a webpage or document or within the data source, which the AI tool reads and the model is then implemented as such, as though it was the user who entered the instructions. The model is by itself may be spotless. The vulnerability occurs purely as a result of a poorly sandboxed plugin or integration.
A study done by asiapacific.org offers a train of hidden risks of LLM supply chain with the particular focus on this plugin and integration layer.
Who Are the Stakeholders Across All These Stages?
A Quick Map
| Stage | Key Stakeholders |
|---|---|
| Data Collection | Data engineers, dataset curators, open data maintainers |
| Training / Fine-Tuning | ML researchers, third-party model providers, open-source community |
| Model Packaging | MLOps teams, model registries, signing infrastructure teams |
| Deployment | DevOps, cloud providers, API platform engineers |
| Plugins / Integrations | Third-party developers, extension marketplaces, end-users |
In this chain all the stakeholders are the possible weak links but not necessarily with an ill intent but by neglect, under-investment or absence of security best practices that are not standardized.
What’s Already Here vs. What’s Just Beginning
Mature Today
- SLSA framework of provenance and integrity of artifacts.
- OWASP LLC Top 10 as a threat taxonomy base.
- NIST AI RMF Government and risk management.
- Sigstore/Cosign of signing (borrowed model) of software supply chain.
- CylonedX ML-BOM of documentation of model component.
Still Developing
- AI/ML system Predictive Vulnerability Analysis – With the use of historical CVE databases and architecture model indicators, predict the points at which vulnerabilities are apt to be created before an attacker starts exploiting them.
- LoRA security review practices and Adaptors are standardized.
- Vetting automated Marketplace of plugins.
- Sharing standards of provenance of cross-organization models.
Specific regulatory frameworks to regulate the LLM supply chain (the current regulation of AI focuses on the output, not the machine that produces outputs) The difference between the not yet mature and the still developing lies in the gap of the most real risk which occurs at present.
Two External Trust Boosters Worth Curling.
These are the official external sources that you may cite them using the next recommended anchor texts:
- LLM Applications OWASP Top 10. Recommended anchoring of the text: OWASP supply chain vulnerability guidance. Apply it to speak about the risks of the plug-in, the training data poisoning, or third party model risks.
- Risk Management Framework of NIST AI. Proposed anchor text: NIST AI Risk Management Framework. Apply it when talking about deployment governance, risk controls or organizational responsibility.
Both are sources in government/standards-body these are those that have high domain authority, are non-commercial and are focused directly on all the stages discussed in this article.
Final Take
The LLM supply chain is not a fictitious theory that security scholars should be concerned about. It is the real way any AI tool executes on raw data to the interface that you are looking at – and this has real, publicly described vulnerabilities at every single step.
Data poisoning does not claim to exist. Base models that are backdoored are passed on standard evals. Bad adapters are similar to optimization. Hacked versions get updated automatically. Coding copilots work on context that is not audited by anybody.
The teams who construct and utilize AI tools by 2025 and beyond must take the LLM Supply Chain Security with the strictness it merits in relation to traditional software security – and hopefully such a case will be made before an attack incident proves them right.
The frameworks exist. The threat taxonomy is overlaid. The last thing is the unified adoption, which begins with the discussion of the pipeline.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


