
Table of Contents
What Is ICR – And Why Should Businesses Care Right Now?
ICR vs OCR: The Difference That Actually Matters
OCR has heard its name among most people; Optical Character Recognition. It reads text of images. No problem with clean fonts, standard layouts. However, as soon as the words on a loan application form are written by hand or a Hacky signature emerges on an ID card, OCR will fail.
This is where ICR – Intelligent Character Recognition – comes in.
ICR is more sophisticated document AI. It is trained in response to handwriting, mixed formats, invalid scans and regional script variances. Consider it a smarter brother of OCR, who went through compliance training.
In a study by Shuftipro, the final difference lies herein; OCR is very stiff on fixed templates whilst ICR is adaptable. It picks up new types of documents and reuses machine learning over time, being much more useful to KYC (Know Your Customer) processes where the variation of documents is the rule not the exception.
ICR is not a luxury to a business when it comes to boarding customers in a variety of countries and having customers with their own ID format, a variant of handwriting and different regulatory provisions. It is virtually a necessity.
ICR Apps for Identity Verification: How Businesses Improve Security and Compliance
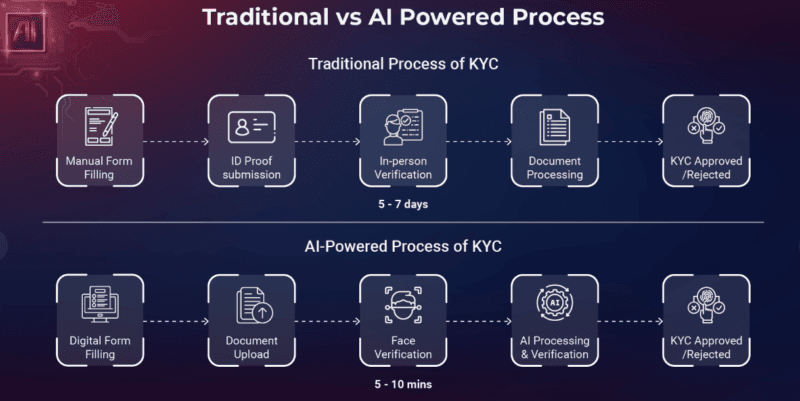
The Typical KYC Flow and Where ICR Fits
The following section is an overview of a typical digital identity verification flow:
- A customer scans or captures a picture of his/her ID (passport, driver license, national ID).
- ICR engine acquires important fields such as name, date of birth, document number, expiry.
- The obtained data is cross-verified with biometric authentication (typically a selfie or liveness verification).
- The system raises a red flag of discrepancies, carries out AML (Anti-Money laundering) screening, and approves or escalates.
I have measured various KYC platforms when assessing products, and the time difference between manual auditing and ICR- assisted extraction is impressive. What once required a compliance analyst several minutes per document is reduced to seconds, experiencing less transcription errors.
Such document processing approaches and intelligent document processing have formed the foundation of the pipeline of identity in platforms such as Ondato or iProov. The extraction itself is not only rapid, it is also organised, auditable and directly purveyed into compliance dashboards.
Why AML Compliance Teams Rely on ICR
Anti-money laundering laws need companies to identify the businesses clients, make such procedures recorded and ready to provide such documents when requested by the regulators. ICR helps on all three fronts.
Robotic field extraction implies no transcription errors. Structured outputs imply that the data would be piped to compliance records. And since ICR systems record all the activities, audit trails are orderly and stampeded.
As my experience demonstrated, achieving the largest compliance win is not velocity but a regularity. There are bad days and good days among human reviewers. ICR doesn’t.
What’s Already Working: The Current State of ICR Technology
Handwriting Recognition at Scale
The ICR engines currently in use can read cursive, print and mixed handwriting in dozens of languages. OCR tools such as Tesseract OCR (open-source) and Microsoft’s Azure Document Intelligence (enterprise-grade) have done well in this regard.
In one example, the Azure Document Intelligence will include passport, driver’s license, and national ID pre-built models – as well as industry-specific trainable models. During testing, I observed that it has confidence scoring is especially handy: as extractions with low certainty are marked and shown to a person instead of propelling bad data down the line.
Biometric Linking
ICR does not work alone. Contemporary identity checking applications connect the information of the documents to facial recognition. The name and the picture taken out of an ID are then compared with a live selfie. It is now normal in regulated industries, such as banking, insurance, telecoms and crypto exchanges.
It is a safer procedure than either check. It is easier to steal an image of a document as compared to a more difficult replica of a live biometric match.
Liveness Detection
Among the less well-known capabilities of apps driven by ICR, is the liveness detection, ensuring that the individual providing the selfie is in actual physical presence, rather than that it is a printed image or a video recording.
It can be related to larger issues of Generative AI Security Risks, especially the deployment of artificial faces and AI-generated verify document images to test verification software. The first line of defense is liveness detection.
What’s Just Beginning: The Next Wave of ICR Improvements
Deepfake-Resilient Biometrics
Deepfakes represent a very real threat to identity verification that is increasing. GenAI has now the ability to generate convincingly realistic faces, voices, and even video sequences. Simple photo matching based systems are becoming more susceptible.
The reaction of the ICR/identity verification sector has been in creating a deepfake resistant biometric authentication, models that seek physiological indicators (micro-expressions, skin texture changes, pupil changes) that artificial faces cannot effortlessly clone.
Literature by iProov points to the fact that the new threat of the attack is now injection attacks (after passing directly into the verification pipeline), as opposed to presentation ones (holding up a photo). Next-generation ICR apps are being developed to protect against both.
This completely intersects with the larger conversation of Generative AI Security Risks – of which compliance and security teams cannot consider as a hypothetical concern.
Adaptive Self-Learning Models
Statics ICR models become obsolete. Forms of documents evolve, additional types of ID are introduced, fraud patterns are changed. The new generation of ICR apps are self-educating ones, i.e. they modify their recognition models using new data, without having to run complete retraining cycles.
This implies that a system in use today will be able to become smarter as time goes on, and it will produce edge cases more accurately than it has ever encountered. This is important to companies which have many geographies of operation. An Indian Aadhaar card system that works well nowadays can be trained to work with a new regional ID format the following quarter.
On-Device and Privacy-Preserving Processing
An actual change is occurring in the environs of document processing. Historically, ICR systems forwarded document images to cloud servers making it available to process them. That exposes data – documents in transit, documents in third party servers.
The newer architecture processes sensitive data either on-device or in secure enclave(s). This is critical to Data Privacy in AI-Powered Security Systems, particularly in systems such as GDPR (Europe), DPDP (India) and CCPA (California).
Businesses which work with documents on-device can inform regulators -and customers -raw ID images do not leave the device of a user. It is a strong argument of data minimization, and regulators have begun to pay attention.
Explainable AI for Compliance Audits
The question that regulators would prefer to know is why a decision was made by an automated system. What was the reason behind this customer being flagged? Why was this document not welcomed?
The existing ICR systems tend to be black boxes, in that they can generate outputs but do not tell us how. That is being changed by explainable AI (XAI). New ICR systems are under construction to generate readable audit trails: Document rejected all files expiry date field is sure 42 below threshold.
This audit-readiness is related to the Automated Threat Containment frameworks of having automated systems that do not just identify the risk, but they also document how they identify it in a manner that can withstand regulatory examinations.
My Take on the Real Challenges Businesses Face
Document Quality in the Real World
Onboarding is not like in a lab. Users post blurry images in the dark, damaged documents physically, individually screenshots. During my research on the product I realized that the strong ICR systems fail even when the quality of images fails to reach a specific threshold.
The workaround solution is quality gates – instead of letting a poor picture sully the extraction process downstream, the user re-takes the photo.
Handwriting Variability
With self-learning models even highly regional or idiosyncratic handwriting is a challenge. Extraction errors are created by older populations, non-standardized form fills and some regional scripts.
The solution to the industry is confidence thresholds – mark low-confidence extractions to be reviewed by humans as opposed to being automatically approved. It introduces an extra step, but it ensures data integrity.
Regulatory Fragmentation
An organization in the EU, India, and the US will have to deal with three different sets of regulations when it comes to verifying Identity. The integration is still considerable, and ICR platforms more and more provide compliance modules depending on local needs.
My experience demonstrated that this complexity is not taken into account by businesses when opting to choose a vendor – they select a platform that is effective in one region without necessarily verifying its coverage in their next target market.
Synthetic Identity Fraud
A rising fraud resource is synthetic identities which involve the creation of identities based on a mix of experiential and forged information. ICR is not sufficient to identify them as it must be supplemented with database cross-referencing and behavioral analytics.
In the study of digital identity verification conducted by Fenergo, it is observed that the successful KYC systems involve document extraction and continuous monitoring, rather than point-in-time checks.
How Different Teams Can Actually Use ICR Apps
For Compliance and KYC Teams
The onboarding is less manual with less manual data entry and faster with the direct value. ICR extracts, compliance rules filter and human reviewers only look at flagged cases. The outcome is a reduced number of workers to cover a higher amount without compromising the precision.
For Product and Tech Teams
These identities are verified using API-first infrastructure such as platform like Amani. The integration is simple, a couple of API calls and the verification process is integrated directly into a product. No construction at all.
To those teams willing to take it a step further, the Azure Document Intelligence comprehensive training module developed by Microsoft is worth saving. It includes training of custom models and is really well-organized as an introduction of a developer to document AI.
For Business Owners and Decision-Makers
The business case is simple: ICR will minimise onboarding friction, certification overhead and generate audit-ready documentation. The ROI manifests itself in the accelerated activation of the customers and reduced cost per verified user.
The latter can be shown using a case study produced by Aira, which provided a case of an automated loan origination that utilizes intelligent document processing that reduced the turnaround on KYC by a significant margin without compromising regulatory requirements.
Free Resources to Get Started
The above are the top free tools that can be used by anyone interested to learn more about ICR and identity verification:
- Tesseract OCR (GitHub) – Open source OCR engine. Works well to see the workings of character recognition at a code level.
- Azure Document Intelligence Docs – the official docs of Microsoft. Detailed and regularly updated.
- Azure Free Training Module: Free, hands-on, developer-oriented.
- iProov Deepfake Blog – Helpful in becoming familiar with the fraud environment.
- Shuftipro OCR vs ICR Explainer – Great, non-technical description of the difference.
- Fenergo Digital Identity Blog – KYC perspective.
FAQs
What do we mean by ICR in identity checking?
ICR is a term used to describe Intelligent Character Recognition. It is a technology that transforms text, such as handwritten text, into it, in ID documents and forms. In identity verification, it automates the data extraction process of KYC, minimizing manual input and enhancing accuracy.
What is the difference between ICR and OCR?
The OCR reads printed text in fixed format documents. ICR does more, it works with handwriting, scales to different document structures and evolves with machine learning to make itself better. ICR is more reliable in realistic KYC flows of different types of IDs.
Does ICR-verification adhere to GDPR?
It could be, but compliance is a question of implementation. Practices of On-device processing and data minimization are very helpful. Enterprises, considering the actual frameworks applied by the vendor of their ICR, ought to ensure that the model complies with the available frameworks in the marketplace – GDPR, DPDP, CCPA, and so forth.
What are the key fraud risks of ICR apps?
The two largest are document forgery (withing approaches relying on counterfeiting or falsifying IDs) and synthetic identity fraud (constructed identities relying on mixed genuine/counterfeit data). ICR solves the former using cross-referencing of databases and confidence scoring. The second needs more behavioral and transactional levels of monitoring.
Is ICR applicable to KYC of small businesses?
Yes. The API-first platforms such as Amani and Azure Document Intelligence have the flexibility of pricing and integration that can serve startups and SMBs, and not only enterprise teams.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


