
What, you want to use an AI model without knowing where it came from? Well, that’s like eating food that doesn’t have any packaging, no use-by date and no ingredient labels. You might be fine. Or you might not. And, well, “might not” is pretty costly.
That’s where model provenance and model SBOM (Software Bill of Materials) comes into the picture – and if you’re deploying AI systems in 2015 then you need to be familiar with both.
Table of Contents
What Does “Model Provenance” Actually Mean?
Model provenance is like a paper trail, but only the part that you record and audit, and in more detail than most teams currently record. In a nutshell, it’s the record of everything that went into building a model: the data sets on which you trained it, how data sets and the underlying data were filtered and versioned, training configuration, fine-tuning post-training, who did what, when, and evaluation results before it went into production.
It’s AI code provenance, but harder, since AI systems are probabilistic, ever-evolving, and may be built on top of base models we don’t fully own and control.
I’ve seen model deployment teams with tight version control over software but no formal record of the version of the data used to train the model. When things went out of kilter weeks later, it was a nightmare investigation that took days. With something as simple as a model provenance schema, that could have been minutes to hours.
Why Provenance Is Now a Governance Requirement
The National Institute of Standards and Technology (NIST) AI’s Risk Management Framework – updated in 2025 – specifically mentions model provenance, data integrity, and third-party model testing, especially for AI systems used in the public sector and for higher risk AI applications. The NIST Generative AI Profile (AI 600-1) also requires publication of training data (and dependency risks) for generative AI instances.
The same is true of the EU AI Act. During the drafting process, requirements for technical documentation, including data sources, decision-making, and monitoring evidence – were written, and model provenance is the natural form for fulfilling these needs. So this is no longer a security pattern. It will be regulatory infrastructure.
What Goes Into a Model SBOM?
A software SBOM typically includes a list of libraries, packages and their versions. A model SBOM (also known as an ML-BOM or AI-BOM) does so for AI artifacts and can be quite complex.
Here’s the basic metadata fields that people are settling on:
Model identity and source
- Name, version, and architecture
- Source (model hub, vendor, internal)
- License and limiting conditions
Dataset summary
- Data set name, version and data source URL
- Consent and licensing status
- General information on filtering or data pre-processing
- Documenting any known data biases
Training and fine-tuning details
- Training procedure (supervised, RLHF, PEFT, full fine-tune)
- Relevant training hyperparameter (epochs, learning rate, batch size)
- Hardware environment hash
- If any alignment or safety training has been done
Evaluation evidence
- Benchmark results and dates run
- Adversarial/red-teaming results
- Failure modes and limitations
Operational parameters
- Permissible tools, APIs, and index Table of contents
- Safety filters and prompts
- Deployment constraints and environment specs
The format matters too. CyloneDX 1.5+ and above expressly supports ML-BOMs, and SPDX is extending its data structures to cover data-processing phases as well as software. The future is a signed JSON, or YAML, manifest in a model registry with an immutable audit trail.
Now, let’s see how the key elements of an ML-BOM cross the boundaries:
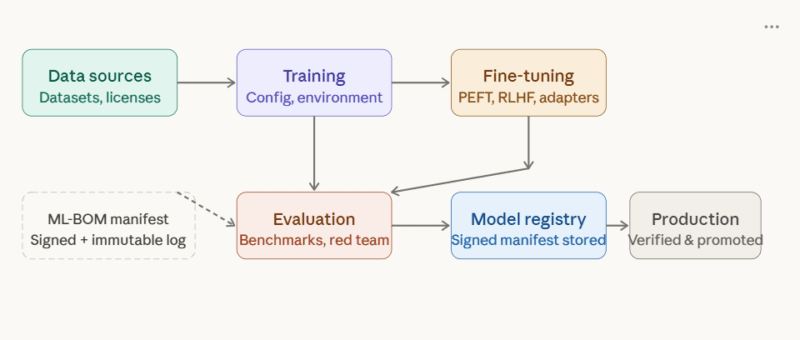
Each step automatically populates provenance into the signed manifest, which is kept in the model registry before being passed through the promotion gates.
When you sign an ML-BOM as a JSON manifest, you'll be able to track four things:
Green dashed box = the ML-BOM artifact as it moves through the pipeline, then gets verified at the production gate.
Why You Must Track These Four Things
Model Origin and Version History
If a model was downloaded from a public hub, fine tuned on a local cluster and then deployed in production, how many teams can answer the questions – which version of the base model? Which version of the fine-tuning code? Which dataset snapshot?
Models aren’t just about version management. If a model has a change in production where the quality of the model changes or the behavior is unexpected, the quickest way to get to the bottom of the issue is to look at the model SBOM and reference the last good version to compare. I’ve observed these teams resolve these issues far faster than teams using informal team messages to try to explain the changes.
This also ties directly to issues surrounding LLM Supply Chain Security – leaving backdoors or poison in the outputs of the base model that cannot be tracked without attestation.
Training Data Summary
Training data is where AI vulnerabilities come from. Biased data is biased output. Poisoned data introduces vulnerabilities. Contaminated data, malicious or by accident, creates security risks that make their way into production-undetected.
The potential pitfalls here are the equivalent of what the IT security industry refers to as LLM05-style supply chain attacks: vulnerabilities introduced not by the code itself, but by the components it’s built on. A model trained on data scraped from the internet with no filtered data record is a liability.
The minimum viable training data record must contain: name and version of the dataset, source information, data consent and licensing information, known biases and limitations, and the filtering applied. That’s not the full check-list – it’s a minimum to allow everything past to be tracked.
It’s the same level of accountabiilty that other industries, such as medical and finance, are requiring. Interestingly, the same provenance push is happening in unrelated sectors: just as “why” hotels are steering clear of OTAs to regain data control in general, “why” AI teams want full control of their models rather than larger vendors’ entire model pipeline.
Dependencies: What Else Is Running?
LLMs are not just a model weight file anymore. They have a collection of corpora, vector representations, message templates, tool invokers, filters, and policies. They are also all conduits for attack.
An SBOM for a model includes all of these runtime components and versions. This is where we see software SBOMs easily translate into model SBOMs: just as an application SBOM would list all the libraries and their versions, a model SBOM lists all the components the model DLs on to include in the SBOM.
Fine-Tuning and Adapter Lineage
Fine-tuning makes this all very messy. Team X fine-tunes base model A to get Model B, Team Y adds an adapter to B for a particular application. By the time this makes it to production, the characteristics of the base model may no longer be at all similar – but if we don’t track the whole model, just its adapter, we can’t trace it.
Each fine-tuning iteration, adapter, and alignment iteration needs to be tracked in a manifest, with a version pointer that at minimum goes back to its base iteration. This is particularly useful to catch data poisoning – one of Machine Learning Anomaly Detection in Cybersecurity’s focus points, relating to peculiar behavior that emerges after deployment.
Patterns for Signing and Verifying Model SBOMs
Documenting model provenance is helpful. And signing is how we make it secure.
The Signing Pattern
The pattern in enterprise MLOps for provenance looks like the following:
- Signatures are automating all metadata into a model registry throughout the production cycle.
- The registry generates a manifest (JSON or YAML) of all the provenance fields.
- The manifest is then digitally signed by the team’s key management infrastructure.
- The manifest is stored, signed, as part of the model Signing doesn’t need to be exotic The
signing exercise need not be complex Many teams use the same tooling they use to secure their DevSecOps process (sigstore, cosign, etc.) that has been extended to work for ML.
CyloneDX 1.5+ allows embedding of ML-BOM content within SBOM content, so that existing tooling stacks can incorporate model provenance “naturally”, rather than having to be rebuilt from scratch.
The Verification Gate
Half of the equation is signing the manifest. The second is ensuring nothing becomes a production artifact without a valid, up-to-date and complete manifest.
The solution that works here is to treat “has a valid signed model SBOM with all required fields” as passing the tests in CI/CD. If there is no manifest, it’s not current or the signature is correct, the build is blocked. Full stop.
This also requires defining your ‘required fields’ before things go into crunch time. In my experience, companies that had a bare minimum schema in place before an incident fared far better. Reconstructed provenance work, especially when done in the heat of an incident, is imperfect.
In the current environment of Zero-Day Vulnerabilities & AI risk, a signed manifest is one of the few risk mitigation controls that security can audit for when something goes wrong in a production environment.
Shadow AI: The Blind Spot
One area to consider is shadow AI. When IT teams use AI models that don’t follow the model manifest process (a developer downloading a local LLM model, a department purchasing an external API without IT approval), the AI models produce no model manifests. No SBOM, no SBOM signature, no audit trail.
It does more than elude governance; it eludes the whole SBOM model process. The only real solution is to make the sanctioned path as easy as possible, and the provenance tooling as seamless as possible, so that it’s harder to go left.
What’s Just Beginning: Where This Is Heading
The tools are getting ahead of the standards. There are a couple to watch:
Composite AI-BOMs – efforts are underway on “packages” that combine a software SBOM (dependencies and runtimes), model card (use cases and limitations), dataset description and fine-tuning provenance into a single securely signed artifact. This eliminates the silos where security, legal, and machine learning personnel each have separate documentation that doesn’t link. Model cards (use case and limitations) – work is also underway to capture intended use and limitations (model cards) in the same unified package.
Automated manifest generation – MLOps and security vendors are beginning to treat the manifest as a natural output of training jobs, rather than something that gets stamped on at the end of the process. This means that starting a job generates the (signed) manifest.
Transformer to the rescue – there are also some experiments generating SBOMs from source and config files using transformer language models. At our current stages this is mainly with software SBOMs, but the idea is starting to trickle through to generate machine learning model SBOMs for poorly documented models.
Policy convergence – the AI Act from the EU, the new NIST AI RMF 2025 (right now in draft), and individual country’s national AI policies all converge on the same needs: technical documentation of data sources, design choices and monitoring. Model SBOMs are required by regulation.
The Practical Starting Point
If the question is what to do first, then the answer is not to design and build a provenance system. The key is to develop a minimum schema and instrument one key service.
A minimal schema must include: model ID and version, license, data summary, high level info on the model training procedure, significant evaluation results, and operational parameters. Correlate each field with NIST AI RMF functions (Govern, Map, Measure, Manage) so risk management and compliance leaders can see the value.
Use that schema in a single training run. Demonstrate that when things go wrong, the manifest points to the cause. There’s the proof of concept that leads to org-wide adoption.
Wrapping Up
Model provenance and model SBOM aren’t about bureaucracy. They’re about being able to answer the question that every production AI system will eventually pose to you: why it’s doing that, and what it’s doing?
Teams which record where it came from, what it was trained on, version and dependencies, and teams which sign and verify manifest before promoting them know for sure. The rest of us just hope.
If you’re shipping AI systems, and you can’t currently generate a signed model SBOM for anything that’s being shipped, that’s where to start.
I’m a technology writer with a passion for AI and digital marketing. I create engaging and useful content that bridges the gap between complex technology concepts and digital technologies. My writing makes the process easy and curious. and encourage participation I continue to research innovation and technology. Let’s connect and talk technology!


